






Cypher
Ako se sad ponovo vratimo na problematiku čuvanja podataka u filmovima, za sada smo objasnili sljedeće: baza dokumenata predstavlja bolju alternativu za čuvanje različitih podataka o filmovima, pogotovo ako se ti podaci mogu međusobno poprilično razlikovati od filma do filma. Međutim što ako nas iz bilo kojeg razloga najviše zanimaju međusobni odnosi između osoba koje su sudjelovale u pripremi pojedinog filma, ako (kao autor teksta) zbilja volite gledati moderne filmove (bar neke žanrove), onda vam je sigurno poznato da pojedine osobe u jednom filmu mogu biti glumci, u drugom scenaristi, a u trećem režiseri (neki režiseri čak pišu i muziku za svoje vlastite filmove), dakle, vrlo složena situacija za modeliranje podataka u relacijskim bazama, ali i u bazama dokumenata.
Koliko podaci mogu biti složeni u graf bazama podataka vrlo jednostavno pokazuje prateća slika uz tekst preuzeta sa stranica poduzeća Cambridge Semantics. Na njoj je prikazano tek nekoliko osoba iz filmske industrije povezanih sa svima dobro poznatim oskarovcem Tomom Hanksom.
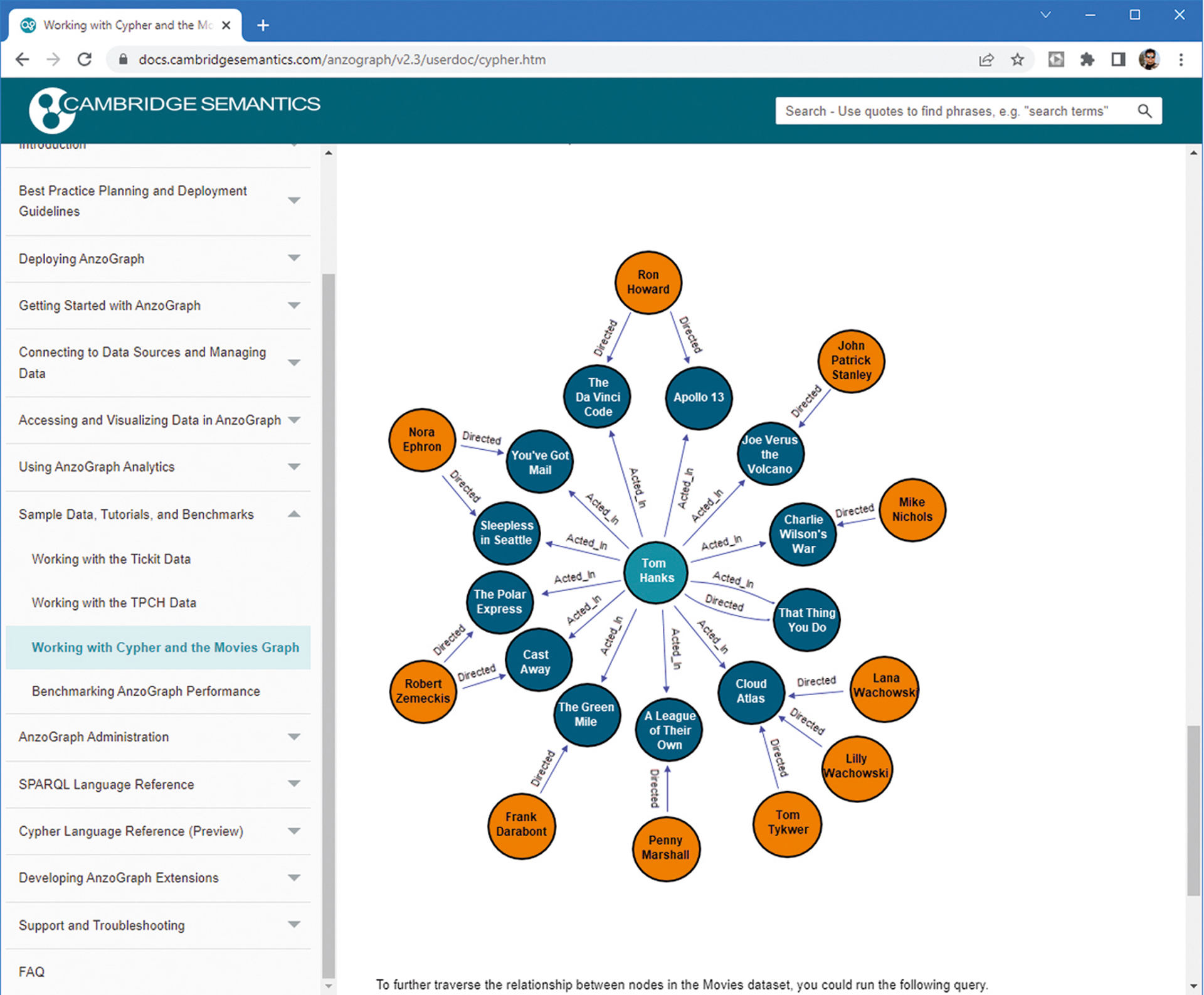
Cambridge Semantics: Primjer kako izgledaju podaci o filmovima u graf bazi podataka.
Tu u igru dolaze graf baze podataka, jer je kod njih ogroman broj međusobnih veza između nodova (u ovom slučaju osoba) nešto sasvim uobičajeno. Sasvim očekivano kod takve organizacije podataka u bazi ni SQL ni MQL ne mogu biti korišteni na odgovarajući način, pa zato u igru ulazi novi jezik upita Cypher. Riječ je o jeziku upita originalno razvijenom od proizvođača najpoznatije graf baze podataka Neo4j. Kasnije su ovaj jezik prihvatili i koriste ga i drugi proizvođači sličnih baza podataka. Na primjer i domaći Memgraph.
Najjednostavniji način na koji možete isprobavati Cypher naredbe je web adresa: https://neo4j.com/developer/cypher/querying/. Na njoj se nalazi čitav niz primjera naredbi čijim izvođenjem se odmah dobije i odgovarajući rezultat.
https://neo4j.com/: Najpoznatija graf baza podataka razvila je svoj jezik upita Cypher.
Koliko je Cypher (i ujedno graf baze podataka) pogodan za rad s različitim vezama među podacima najlakše je demonstrirati pomoću primjera jednakog upita pripremljenog na sličnim bazama u smislu spremljenih podataka (Neo4j i nekoj od relacijskih baza podataka). Primjer s dodatnim objašnjenjima je dostupan na adresi: https://neo4j.com/blog/sql-vs-cypher-query-languages.
Cypher upit (izgleda prilično kratko i jednostavno):
MATCH (u:Customer {customer_id:’customer-one’})-[:BOUGHT]->(p:Product)<- [:BOUGHT]-(peer:Customer)-[:BOUGHT]->(reco:Product)
WHERE not (u)-[:BOUGHT]->(reco)
RETURN reco as Recommendation, count(*) as Frequency
ORDER BY Frequency DESC LIMIT 5;
ali je zato slični SQL upit „malo kompliciraniji“, zar ne?
SELECT product.product_name as Recommendation, count(1) as Frequency
FROM product, customer_product_mapping, (SELECT cpm3.product_id, cpm3.customer_id
FROM Customer_product_mapping cpm, Customer_product_mapping cpm2, Customer_product_mapping cpm3
WHERE cpm.customer_id = ‘customer-one’
and cpm.product_id = cpm2.product_id
and cpm2.customer_id != ‘customer-one’
and cpm3.customer_id = cpm2.customer_id
and cpm3.product_id not in (select distinct product_id
FROM Customer_product_mapping cpm
WHERE cpm.customer_id = ‘customer-one’)
) recommended_products
WHERE customer_product_mapping.product_id = product.product_id
and customer_product_mapping.product_id in recommended_products.product_id
and customer_product_mapping.customer_id = recommended_products.customer_id
GROUP BY product.product_name
ORDER BY Frequency desc
Neo4j Aura DB baza dostupna je za slobodno korištenje u cloudu.
Naravno opis postavljanja upita na bazu Cypher omogućava i pripremu objekata u bazi (ranije spomenutih čvorova, veza i svojstava). Na primjer:
MATCH
(a:Person),
(b:Person)
WHERE a.name = ‘A’ AND b.name = ‘B’
CREATE (a)-[r:RELTYPE {name: a.name + ‘<->’ + b.name}]->(b)
RETURN type(r), r.name
Za kraj
Ako ste do sada samo čuli za i/ili u praksi koristili relacijske baze podataka, možda čitanjem ovog teksta dobijete ideju kako bi za neki problem iz prakse bilo bolje iskoristiti alternativni pristup u modeliranju podataka i postavljanju upita. Što (budimo realni) nije uvijek jednostavno primijeniti u stvarnosti. Pogotovo ako radite u poduzeću koje godinama koristi isključivo relacijske baze podataka i već je investiralo ogromne količine vremena i sredstava u razvoj na njima temeljenih aplikacija. Međutim, ako ste startup koji kreće ispočetka, onda primjena drugačijeg pristupa u rukovanju podacima (ako to ima smisla) vjerojatno i nije toliko komplicirana, a može dati bolje rezultate nego korištenje relacijskih baza podataka.