






Arhitekture su zadnjih godina sve prisutnije u praksi za spremanje i obradu različitih vrsta podataka, što posebno vrijedi za različite konfiguracije oblaka. To su:
- Data Warehouse (skladište podataka)
- Data Lake (jezero podataka)
- Data Lakehouse (?)
Budući da su se prva dva pojma (posebno prvi) i pripadajuće tehnologije u pozadini već prilično raširile u svakodnevnom korištenju, u današnjem tekstu ćemo se detaljnije pozabaviti posebnostima zadnje od nabrojenih arhitektura. Za koju tek treba pronaći pravi hrvatski naziv. Zato ćemo za nju u nastavku teksta koristiti originalni naziv lakehouse.
Dok su podaci u skladištu podataka spremljeni u dobro strukturiranom obliku (najčešće u obliku relacijskih baza podataka), te kao takvi odmah dostupni za korištenje u različitim alatima, u jezeru podataka se čuvaju u svojem izvornom obliku (na primjer, različiti formati poslovnih dokumenata). To znači da se u jezeru podataka mogu zajedno čuvati i strukturirani (najčešće su to relacijski) podaci, ali i različite vrste polustrukturiranih ili nestrukturiranih podataka.

Razlike među arhitekturama: Data Warehouse, Data Lake i Data Lakehouse
Glavni problem s jezerom podataka je u tome što takva raznolikost podataka otežava njihovo izravno korištenje. U pravilu se prije samog korištenja (pogotovo ako se zajedno koriste različite vrste podataka) nad podacima treba napraviti nekakva vrsta obrade. Ponekad je čak i uz pomoć takvih dodatnih obrada teško izbjeći redundanciju ili osigurati postojanje transakcija tijekom obrade.
Zato u igru ulazi lakehouse arhitektura, koja pokušava pomiriti razlike između skladišta i jezera podataka. Lakehouse i dalje dozvoljava spremanje različitih vrsta podataka kao jezero podataka, ali u njemu također postoje dodatni metapodaci koji omogućavaju da se takvi „rasuti“ izvori podataka po svojim mogućnostima mogu usporediti s relacijski organiziranim podacima. U nastavku teksta usmjerit ćemo se na to kako je korištenje ovakve arhitekture podataka u praksi zamislio Microsoft. Ali također može poslužiti kao polazište za istraživanje rješenja drugih tvrtki (Amazon, Google...).
Microsoft Fabric i OneLake
Microsoft Fabric predstavlja jedinstvenu platformu za bilo koju razinu veličine tvrtke namijenjenu za uvoz, obradu, premještanje i ostale operacije nad podacima potrebne na različitim područjima rada s podacima kao što su Data Engineering, Data Factory, Data Science, Real-Time Analytics, Data Warehouse…). Umjesto da se podaci čuvaju u različitim oblicima izvornih podataka, svi se oni spremaju zajedno u centraliziranom lakehouse sustavu – OneLake. Kao što je to danas već uobičajeno, u sustav su integrirana još dva danas praktično nezaobilazna elementa – podrška za AI (Copilot in Fabric) te upravljanje sigurnošću podataka (Microsoft PurView). Sasvim očekivano, sve skupa je jednostavno povezivo s drugim Microsoft tehnologijama kao što su Microsoft 365 ili Power BI.
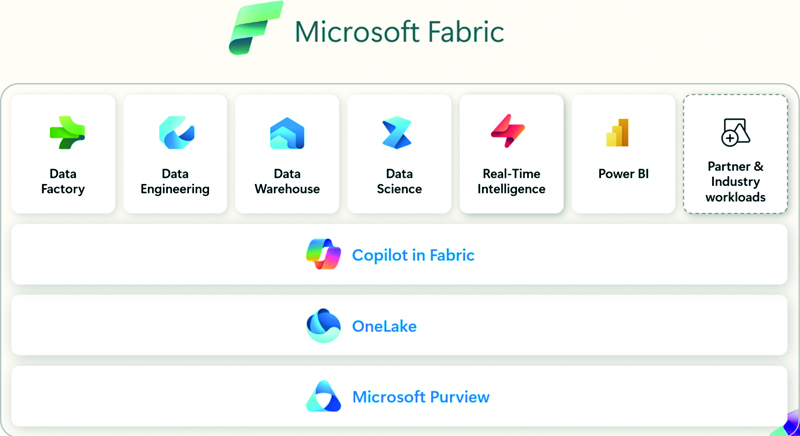
Microsoft Fabric: Glavni dijelovi sustava
Od brojnih pojmova navedenih u prošlom paragrafu, u nastavku teksta usredotočit ćemo se na OneLake, kao Microsoftovu implementaciju lakehouse tehnologije. OneLake se u radu oslanja na osnovnu tehnologiju pod nazivom ADLS (Azure Data Lake Storage) Gen2. Ali je u ovom slučaju sve skupa bitno pojednostavljeno, kako bi se što jednostavnije moglo koristiti u praksi bez poznavanja temeljnih tehnologija. Na primjer, nije potrebno detaljnije poznavati Azure resurse ni resursne grupe, korištenje redundancije podataka i regija za njihovo spremanje, i druge slične tehnologije.
Također, OneLake bitno pojednostavljuje međusobnu suradnju većeg broja IT stručnjaka na istim projektima. U ovom slučaju, riječ o jedinstvenom sustavu za spremanje podataka različitih korisnika, a ne većem broju pojedinačnih i međusobno izoliranih spremišta za pojedinačne korisnike ili grupe korisnika podataka.
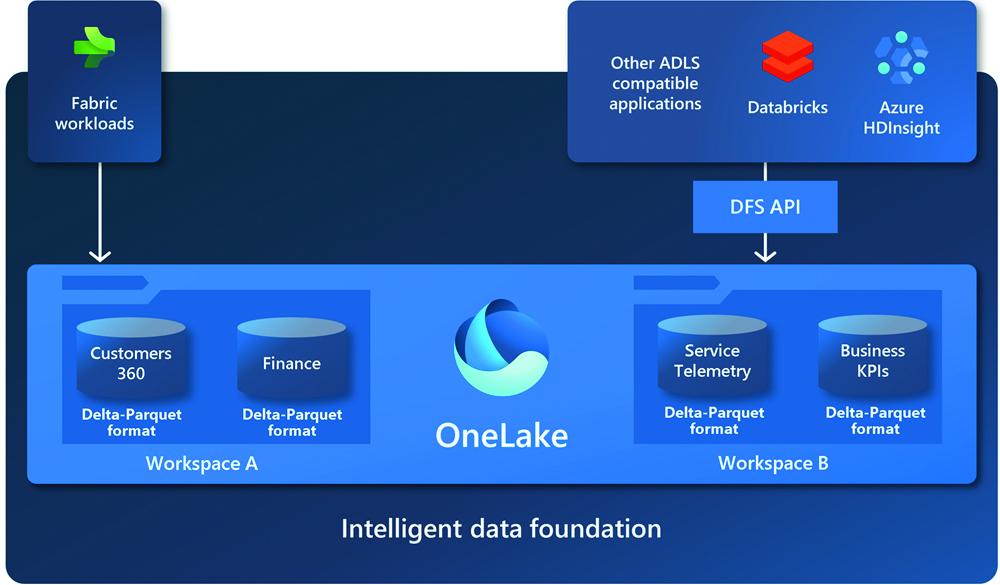
Microsoft OneLake: Microsoft „pogled“ na lakehouse arhitekturu
Podaci su u okviru jednog OneLake sustava organizirani hijerarhijski u spremnike (containers) i radne prostore (workspaces) u kojima se mogu čuvati različite vrste podataka. Organizacija OneLake elementa može se usporediti s organizacijom diska s mapama i podmapama. Pri tome (sa stanovišta korisnika) nije bitno prostire li se OneLake preko više različitih korisničkih računa ili regija.
U slučaju da korisnik već posjeduje veliku količinu podataka u nekakvom izdvojenom spremištu u drugačijoj tehnologiji (na primjer, Amazon Web Service AWS) nije ih potrebno prvo uvoziti u OneLake da bi se uopće mogli nekako iskoristiti. Dovoljno je na njih postaviti svojevrsne prečace (shortcuts). Za taj postupak se može koristiti vizualno grafičko sučelje ili odgovarajući REST API poziv. Osim postavljanja prečaca na vanjske izvore podataka, to isto moguće je napraviti na druge dijelove sustava koji se nalaze unutar samog OneLake spremišta.
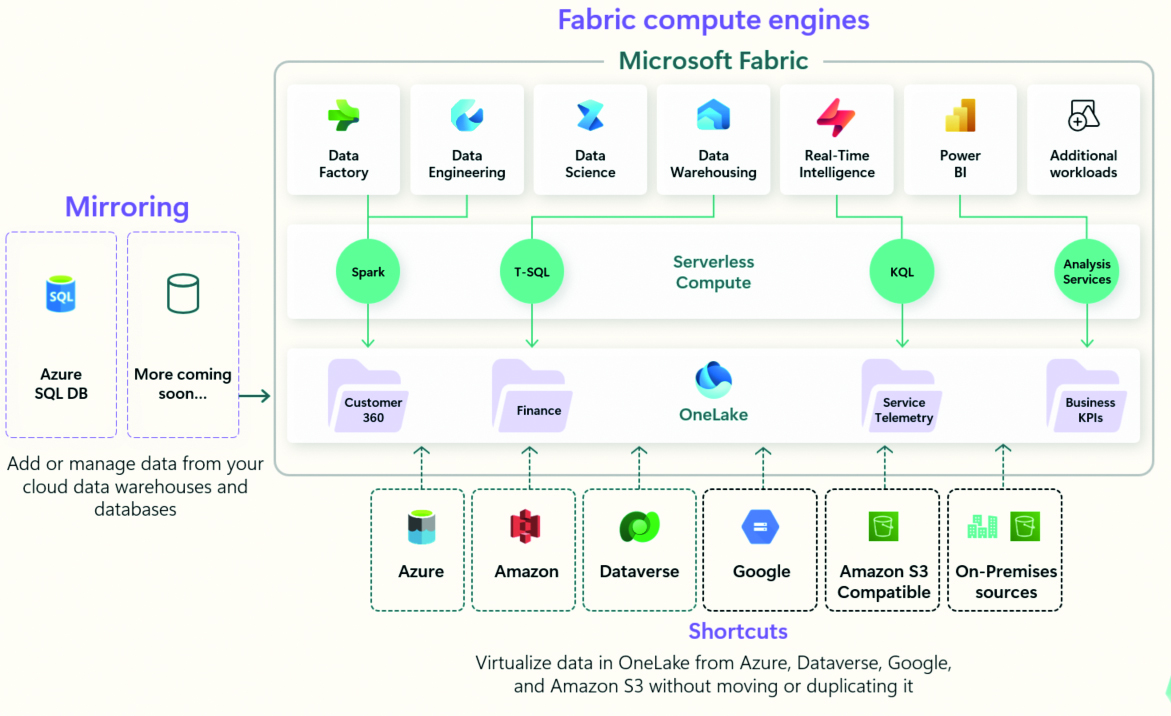
Prečaci omogućavaju povezivanje OneLake sustava s različitim drugim izvorima podataka bez njihovog kopiranja
Pri tome su prečaci potpuno nezavisni objekti od samih podataka. To znači da brisanje prečaca ni na koji način ne utječe na same podatke, dok brisanje podataka rezultira time da prečaci više nisu relevantni.
Probajmo sad malo detaljnije opisati internu strukturu podataka unutar OneLake sustava. Na samom vrhu interne strukture nalaze se mape Tables i Folders. Mapa Tables namijenjena je čuvanju strukturiranih podataka pod svojevrsnim nadzorom sustava, dok je mapa Folder namijenjena slobodnom čuvanju svih drugih oblika podataka. Na primjer, nestrukturiranih i polustrukturiranih.
Delta tables i ostale povezane tehnologije
Sami podaci „pod nadzorom sustava“ se u okviru OneLake sustava spremaju u takozvane Delta tablice. Riječ je o pojmu predstavljenom zajedno s Data Lake tehnologijom, kao temelj za spremanje podataka u lakehouse. Delta tablice omogućuju rukovanje transakcijama u stvarnom vremenu, a istovremeno su pogodne za rad s velikim kolekcijama podataka (big data). Sa stanovišta same implementacije, nastale su nadogradnjom osnovnog Parquet formata zapisa podataka (u kojem se zajedno čuvaju podaci iz iste kolone, a ne retka tablice) posebnim transakcijskim log dodacima. Zato Delta tablice osim samog spremanja podataka imaju ugrađenu podršku za:
- Izvođenje ACID (Atomicity, Consistency, Isolation i Durability) operacija nad podacima, što je vrlo važno za čuvanje njihove konzistentnosti.
- Povijesni pregled podataka, što znači da se stanje podataka zapisanih u takvim tablicama može pratiti u bilo kojem trenutku u povijesti.
- Vrlo striktnu kontrolu podataka koji se zapisuju u tablice, pa se zato u njih ne mogu zapisati podaci koji nisu u skladu sa zadanim pravilima
- Podržavaju različite tehnike optimizacije za brži rad (keširanje, indeksiranje, i slično).
Budući da je riječ o formatu u javnom vlasništvu, ovu tehnologiju moguće je koristiti u kombinaciji i s drugim najpoznatijim sustavima oblaka (AWS i GCS).
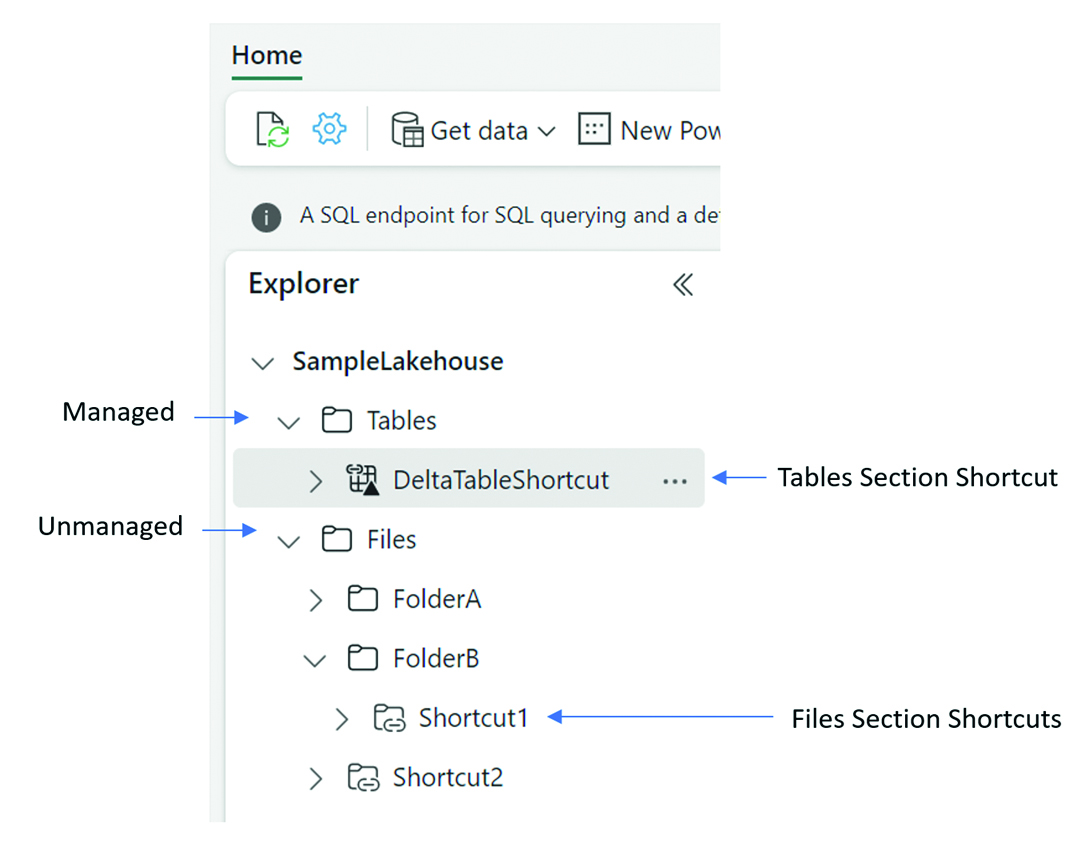
Tables i Files: Elementi na vrhu hijerarhijske strukture u sustavu OneLake
Svojevrsnu nadogradnju Delta tablica predstavljaju Delta Live tablice, a glavna zadaća im je olakšavanje različitih ETL procesa kakvi se koriste u okviru lakehouse sustava. Uobičajeni način izvođenja takvih operacija je korištenje cjevovoda, a upravo korištenje Delta Live tablica olakšava definiranje takvog procesa na deklarativni način. Istovremeno osiguravajući i različite sigurnosne mehanizme kao što su nadzor i osiguravanje kvalitete podataka, obrada pogrešaka i slično. Uz pomoć Delta Live tablica moguće je napraviti deklarativno opisivanje načina na koji podaci teku među tablicama te po potrebi inkrementalnu obradu podataka, što je vrlo bitno kod optimizacije obrade na velikoj količini podataka.
Za kreiranje Delta tablica mogu se koristiti različite tehnologije. Evo dva primjera (SQL i Python):
CREATE TABLE students_info (
id INT,
name STRING,
age INT
)
USING DELTA
LOCATION '/user/hive/warehouse/student_info'
%python
# Databricks Delta Table example
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
# Define the schema
schema = StructType([
StructField("id", IntegerType(), True),
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)
])
# Create an empty DataFrame with defined schema
df = spark.createDataFrame([], schema)
# Writing empty DataFrame as a Delta table
df.write.format("delta").saveAsTable("students_info_dataframe")
# or
# or df.write.format("delta").save("/path/to/delta/…")"
Osim spomenutih temeljnih „Delta“ tehnologija (tablica), korisnicima je dostupno još nekoliko bitnih dodataka, kao što su:
Delta Sharing
Omogućava dijeljenje podataka između različitih tvrtki bez obzira na platformu koju koriste unutar tvrtke. Riječ je o REST protokolu preko kojeg se može pristupati podacima spremljenim na različite načine bez potrebe da se oni prvo kopiraju na određenu platformu.
Delta Engine
Optimizator upita za velike količine podataka koje mogu postojati u lakehouse sustavima.
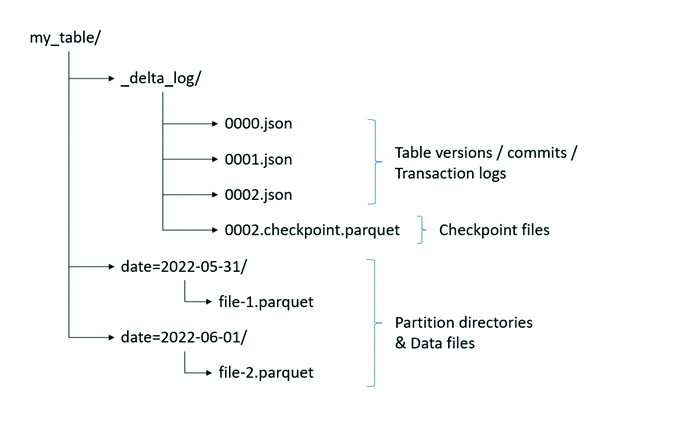
Delta table format sastoji se od Parquet datoteka i dijela za bilježenje transakcija
U slučaju da se želite detaljnije upoznati s Microsoft Fabric i OneLake tehnologijama (te drugim pojmovima spomenutim u ovom tekstu), onda to možete napraviti u ograničenom vremenskom periodu potpuno besplatno pomoću Microsoft Azure platforme.