






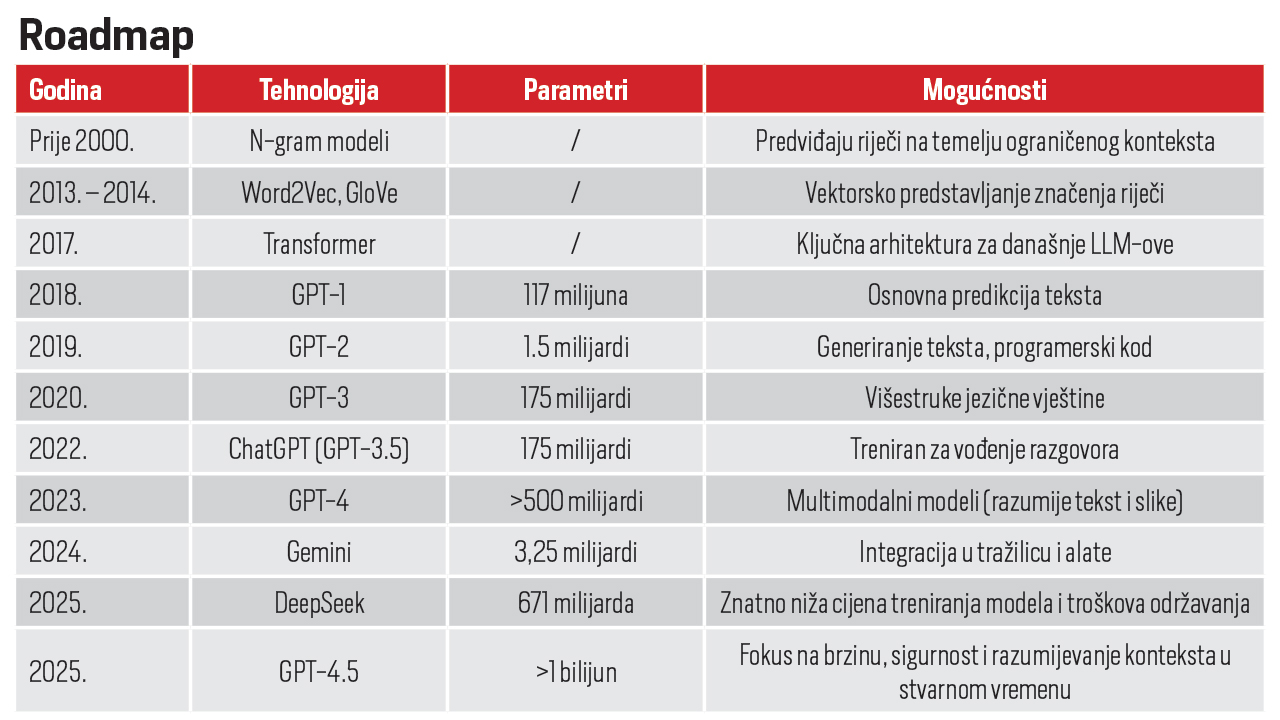
Veliki jezični modeli (LLM – Large Language Models) predstavljaju jednu od najvažnijih prekretnica u razvoju umjetne inteligencije. Suvremeni sustavi umjetne inteligencije sve se više oslanjaju na modele koji nisu strogo utemeljeni na pravilima, već na podacima i obrascima naučenima iz ogromnih skupova podataka. Danas su veliki jezični modeli sposobni analizirati, razumjeti i stvarati jezični sadržaj gotovo na razini ljudske interakcije, čime uvelike proširuju mogućnosti tehnologije u svakodnevnom i profesionalnom okruženju, te imaju sve širu primjenu u obrazovanju, industriji, zdravstvu, tehnologiji, ali i svakodnevnom korištenju za osobne potrebe. LLM-ovi koriste ogromne količine teksta iz knjiga, članaka, web stranica i drugih izvora da bi naučili obrasce u jeziku – kako se riječi povezuju i kako ljudi prirodno komuniciraju. Razvoj jezičnih modela seže gotovo četrdeset godina u prošlost kad su se koristili statistički modeli jezika, poput n-gram modela, koji su predviđali sljedeću riječ na temelju nekoliko prethodnih, no oni su bili ograničeni jer nisu mogli razumjeti duži kontekst. Prvi veći iskorak u razvoju jezičnih modela smo imali u dvijetisućitim razvojem obrade prirodnog jezika (NLP), kad su se pojavili složeniji modeli poput TF-IDF i vektorskog predstavljanja značenja riječi Word2Vec i GloVe, koji su omogućili bolje razumijevanje odnosa među riječima, no još uvijek ne i cijelog konteksta. Prekretnica se dogodila 2017. kada je Google predstavio Transformer arhitekturu u radu “Attention is All You Need”. Ta arhitektura je temelj za sve moderne LLM-ove. Nakon Transformera, počinje rapidan rast i razvoj LLM-ova i ulazimo u modernu eru umjetne inteligencija koja i dalje nezaustavljivo raste. OpenAI 2018. godine predstavlja GPT-1, prvi veliki jezični model sa 117 milijuna parametara i osnovnom predikcijom teksta. Godinu dana kasnije, izašla je nova generacija GPT-2 s 1,5 milijardom parametara, koji je mogao generirati tekstove i programski kod, te izazvao popriličnu pažnju javnosti zbog realističnog jezika koji je sve više nalikovao ljudskom.
Idućom generacijom, LLM je narastao na čak 175 milijardi parametara i imao značajno poboljšanje u razumijevanju, ali i generiranju jezika. GPT-3 označava početak komercijalne primjene LLM modela, no još uvijek u ograničenim okvirima chatbotova i drugih aplikacija. Prava revolucija će uslijediti dvije godine kasnije, 2022. kad na tržište izlazi ChatGPT zasnovan na LLM modelu GPT-3.5. Popularni ChatGPT je preko noći postao svjetski fenomen koji su svakodnevno koristili milijuni ljudi. Prvi je to model koji je treniran za interaktivno vođenje razgovora i ima ljudsku reakciju na svako postavljeno pitanje. Nije trebalo dugo čekati na odgovor drugih velikih kompanija, jer je već iduće godine Google prestavio Bard (današnji Gemini), a Anthropic je izdao prvu generaciju Claude LLM-a. Iste godine izlazi GPT-4 s više od 500 milijardi parametara koji „razumije“ tekst i slike, te ima veću preciznost u generiranju teksta. Taj oblik koristimo i danas u besplatnim inačicama AI alata. Daljnjim razvojem, dolazimo do prošle godine kad je predstavljen GPT-4.5 (službeno je izašao tek u veljači ove godine), koji je stavio veliki fokus na brzinu, sigurnost i razumijevanje konteksta u stvarnom vremenu. No, novi igrač im je pomrsio planove i početkom ove godine izlazi DeepSeek, kineski LLM koji je izazvao popriličnu zbrku na AI tržištu. Naime, za samo šest milijuna američkih dolara je istrenirao model za koji je GPT-u trebalo stotinu milijuna dolara i troši desetinu snage za operativan rad.
Pokazao je da LLM-ovi ne moraju biti zahtjevni i skupi za održavanje kako smo ranije smatrali. Također, radi se o open source projektu za koji ne naplaćuje korištenje, već samo upite putem API-ja, no po znatno nižim cijenama od konkurencije. No LLM-ovi nisu dosegli ni približno svoj limit, čak ni plato razvoja u kojem će skokovi biti sve manje osjetni. Dapače, razvijaju se brže no ikad.
Svijetla budućnost ili sudnji dan?
Što možemo očekivati od LLM-ova u naredne tri godine? Oni će u narednim izdanjima imati stabilnije i pouzdanije modeli, što će rezultirati s manje halucinacija. To je općeprihvaćeni izraz kad GPT model izmišlja činjenice koje ne provjerava prije generiranja, a zbog čega su informacije dobivene od LLM-ova i dalje nepouzdane za korištenje bez naknadne samostalne provjere. Očekuje se i bolje razumijevanje konteksta i nijansi jezike, te više „zdravog razuma“ i dosljednosti kod pisanja odgovora, pogotovo u dužim seansama, odnosno chatovima. Očekuje se da će se umjetna inteligencija na pametnim telefonima ponašati kao stalni virtualni asistenti koji će pamtiti korisnikove stilove pisanja, preference, projekta, omiljene restorane i mjesta, te na naučenim obrascima sastavljati mailove, rezervirati usluge i mjesta i druge repetitivne zadaće. Očekuje se i standardizacija multimodalnosti, pa će tako bolje analizirati, ali i generirati druge oblike multimedije, poput slike, zvuka i video zapisa. Moćne AI alate će trebati bolje regulirati, pa tako očekujemo donošenje i provedbu AI akta Europske unije, koji će se baciti transparentnosti modela, ograničenjem zloupotrebe poput deepfakea, ali i pitanjem autorskih prava i podijele odgovornosti, osobito kod automatizacije umjetne inteligencije u prometu, industriji i drugim granama.
Ovo je tek jedan od recepata iz naše VIDI AI kuharice
 |
Nastavite s čitanjem ostalih poglavlja i cjelina unutar serijala "VIDI AI kuharica"Početna prašina oko generativnog AI se donekle slegla i još nas većinom nije zamijenila umjetna inteligencija. No, i dalje je i sve više oko nas, a ti se alati s predznakom AI-a s malo znanja mogu iskoristiti kao nadogradnja vaših poslovnih ili privatnih alata. Zaronili smo u vrlo napućen svijet AI alata i izronili s našom kuharicom u kojoj možete naći gotove recepte ili samo sastojke s kojima uz malo truda vi možete stvoriti svoj recept. |