






Ako se niste tek od ovog broja časopisa VIDI otisnuli u IT svijet, onda vam je svakako poznato da se podaci u modernim IT sustavima čuvaju i koriste u različitim tipovima sustava za upravljanje bazama podataka. Neki od najpoznatiji tipova su relacijske baze podataka, baze dokumenata i graf baze podataka.
Među vladajućim tipovima baza podataka na tržištu (što pokazuje i prateća slika uz tekst) upravo su tri navedene vrste sustava za upravljanje bazama podataka. Naravno, među njima je još uvijek prilično dominantan najpoznatiji, relacijski model baza podataka.
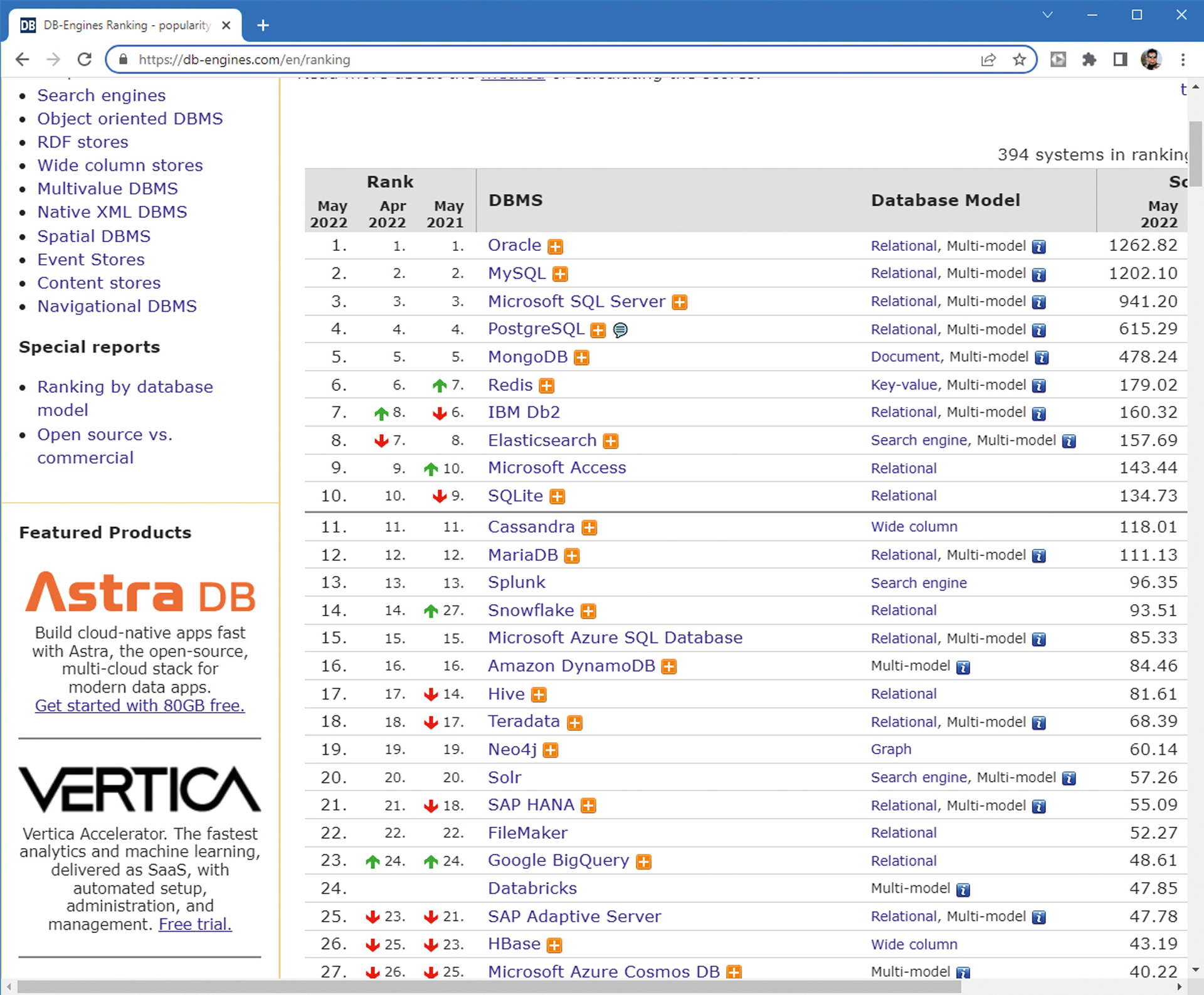
Pregled najpopularnijih baza podataka (i njihovih tipova).
Kod relacijskih baza podataka podaci se čuvaju u obliku slogova/redova u većem broju unaprijed pripremljenih tablica, a one su međusobno povezane relacijama. Podaci u tablicama moraju biti normalizirani, što u osnovi znači da se podaci u tablicama ne smiju ponavljati niti biti izravno međuovisni. Uz brojne prednosti u korištenju povezane sa stabilnošću, performansama, podrškom za različite tipove podataka i slično, jedan od najvećih problema korištenja relacijskih baza podataka postaje uočljiv kad u bazi podataka treba čuvati podatke o vrlo različitim vrstama objekata iz stvarnog svijeta. Na primjer, detaljne karakteristike međusobno vrlo različitih proizvoda za prodaju u trgovačkim lancima. Ako se u tablice dodaju stupci za čuvanje svih mogućih podataka za takve proizvode, onda je u pravilu dio stupaca uvijek prazan za proizvode koji nemaju određena svojstva. Ako se kod nekog proizvoda pojavi potpuno novo svojstvo, onda prvo treba izmijeniti tablicu (dodati stupac) za čuvanje takvog svojstva. Kod čitanja podataka iz baze podataka potrebno je ponovo spojiti podatke iz različitih tablica kako bi se dobio željeni rezultat.
Najpoznatiji proizvodi iz grupe relacijskih baza podataka su Oracle, SQL Server, MySQL, MariaDB, PostgreSQL, IBM DB2 i tako dalje.
Baze dokumenata uklanjaju jedan od najvećih problema u korištenju relacijskih baza podataka, a to je spremanje nestrukturiranih podataka, kakvih je sve više na različitim područjima ljudskog djelovanja. Umjesto da se podaci spremaju u unaprijed definirane tablice fiksne strukture, svaki dokument u bazi može imati različite atribute. Nije neophodno ni da svi dokumenti imaju sve atribute, nego samo one koji se stvarno koriste za određeni objekt.
Istovrsni dokumenti međusobno su povezani u kolekcije dokumenata, a dokumenti i kolekcije automatski nastaju prilikom zapisivanja podataka u bazu podataka. Nema potrebe za prethodnim definiranjem sheme kolekcija dokumenata i samih dokumenata, kako bi se moglo započeti sa spremanjem podataka.
Još jedna od velikih prednosti baza dokumenata je to da se kolekcije podataka mogu podijeliti na veći broj jeftinijih servera (sharding operacija), čime se prilično jednostavno i jeftino mogu podići cjelokupne performase sustava.
Najpoznatiji predstavnici baza dokumenata su MongoDB, Couchbase, Firebase, i ostali. Kao primjer jezika za upit na baze dokumenata može se navesti MQL, koji je razvijen i koristi se u bazi podataka MongoDB, odnosno u njezinoj cloud verziji Atlas.
Kod podataka s vrlo složenim i različitim oblicima veza između podataka, ni jedna od spomenute dvije vrste baza podataka (relacijske baze i baze dokumenata) najčešće ne može optimalno riješiti sve zahtjeve. U takvim situacijama najbolje rezultate u pravilu daju graf baze podataka. Kod ovakve organizacije podataka temeljni elementi za predstavljanje podataka su čvorovi (nodes). Svaki čvor može sadržavati veći broj različitih svojstava predstavljenih u obliku ključ/vrijednost (key/value). Čvorovi u modelu mogu biti u različitim vrstama odnosa, što je predstavljeno linijama između njih. Kako bi se što preciznije upravljalo spremanjem i korištenjem različitih vrsta podataka, svojstva čvorova podržavaju uobičajene tipove podataka (npr. Integer, Float, Boolean, String, List i ostalo).
Neki od predstavnika iz ovakve grupe baza podataka su Neo4j, TigerGraph i Memgraph.
Pristup podacima
Za spremanje podataka i za njihovo naknadno čitanje sve baze podataka koriste neku vrstu jezika upita. Budući da se različite vrste baza podataka (kao što to prikazano u prethodnom dijelu teksta) međusobno poprilično razlikuju, teško da jedan jezik upita može zadovoljiti sve potrebe. Zato nije ni čudo da je za svaku od spomenutih tipova baza razvijen poseban jezik upita. Tema kojom ćemo se pozabaviti u nastavku teksta.
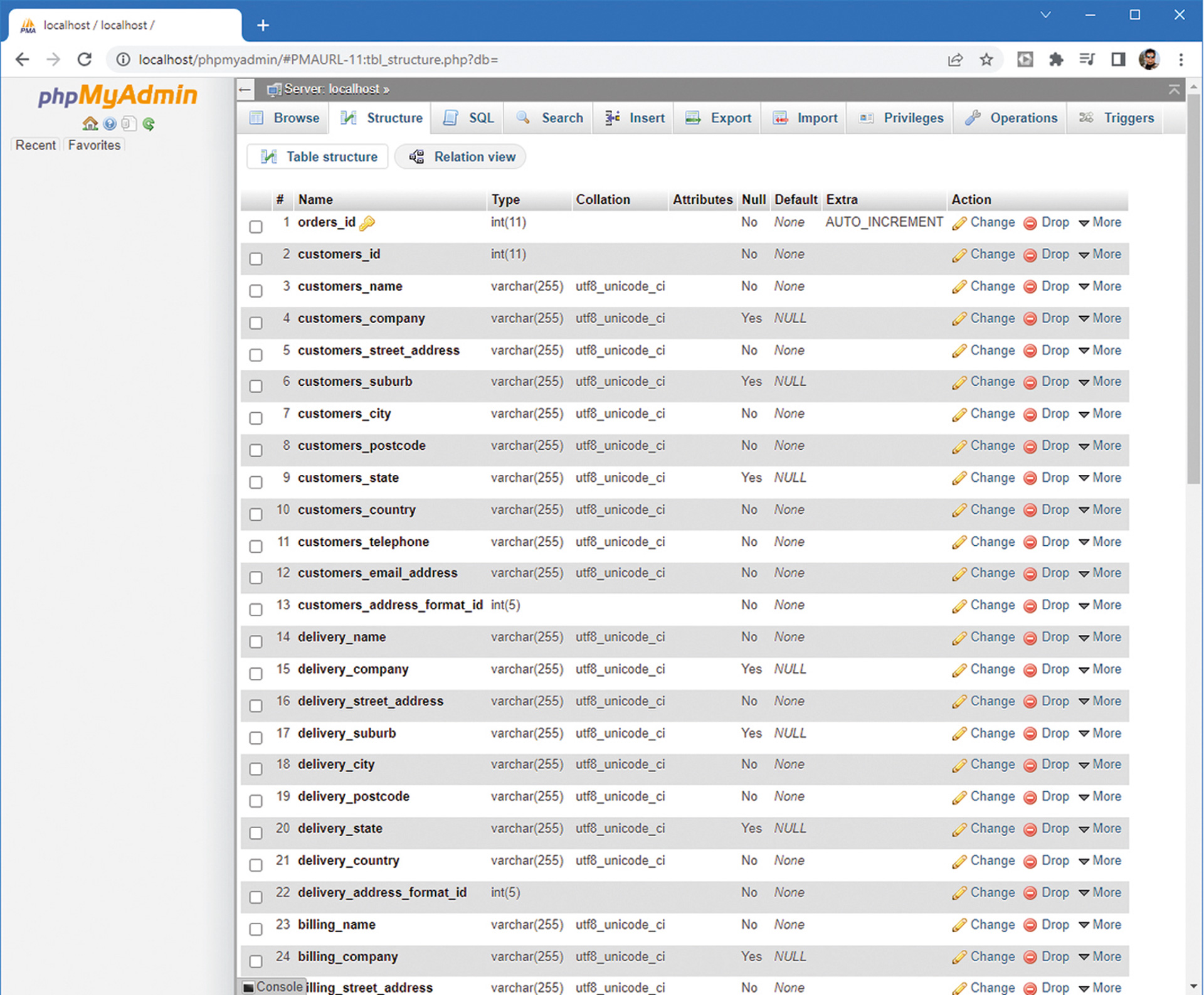
Relacijske baze podataka za spremanje podataka treba pripremiti tablice prije korištenja.
Kako bi se programerima olakšalo korištenje različitih tipova baza podataka u vlastitim aplikacijama, pojedini programski jezici i prateći „Framework“ sustavi često uspijevaju u velikoj mjeri sakriti te razlike prilikom pisanja programskog koda, ali to je već tema za neku drugu priliku. Ovaj put pozabavit ćemo se osnovnim jezicima upita za svaku od ranije spomenutih kategorija baza podataka.
Budući da svaki jezik upita podržava čitav niz različitih sintaksnih detalja, kako bi se iskoristile sve mogućnosti pojedine vrste baza podataka, za svaki od njih postoje čitave serije knjiga i seminara za detaljno upoznavanje. Zato ovaj tekst prije svega ima za cilj da steknete uvid u osnovne razlike među različitim vrstama jezika upita. A to je najlakše prikazati na postavljanju upita na već spremljene podatke u bazama.
SQL
Za rad s relacijskim bazama podataka koristi se SQL (Structured Query Language). Iako se nad SQL-om već godinama provodi standardizacija, različiti proizvođači baza podataka u jezik dodaju svoja vlastita proširenja, zbog čega se često isti upiti ne mogu izravno izvoditi na drugim relacijskim bazama podataka.
Naredbe SQL jezika mogu se podijeliti u četiri velike grupe:
DDL – Data Definition Language (definiranje različitih objekata u bazi podataka)
DQL – Data Query Language (postavljanje upita nad postojećim podacima u bazi)
DML – Data Manipulation Language (rukovanje podacima – dodavanje, izmjena, brisanje)
DCL – Data Control Language (dodjeljivanje prava na korištenje pojedinih objekata)
Evo primjera nekoliko povezanih DDL naredbi za kreiranje tablica i pratećih objekata u MySQL bazi podataka. Neophodno je detaljno opisati svaki stupac tablice, kao i sve potrebne prateće objekte poput primarnih ključeva ili indeksa.
DROP TABLE IF EXISTS `orders`;
CREATE TABLE IF NOT EXISTS `orders` (
`orders_id` int(11) NOT NULL,
`customers_id` int(11) NOT NULL,
`customers_name` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`customers_company` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`customers_street_address` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`customers_suburb` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`customers_city` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`customers_postcode` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`customers_state` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`customers_country` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`customers_telephone` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`customers_email_address` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`customers_address_format_id` int(5) NOT NULL,
...
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
ALTER TABLE `orders`
ADD PRIMARY KEY (`orders_id`),
ADD KEY `idx_orders_customers_id` (`customers_id`),
ADD KEY `idxSCCode` (`sccode`);
ALTER TABLE `orders`
MODIFY `orders_id` int(11) NOT NULL AUTO_INCREMENT
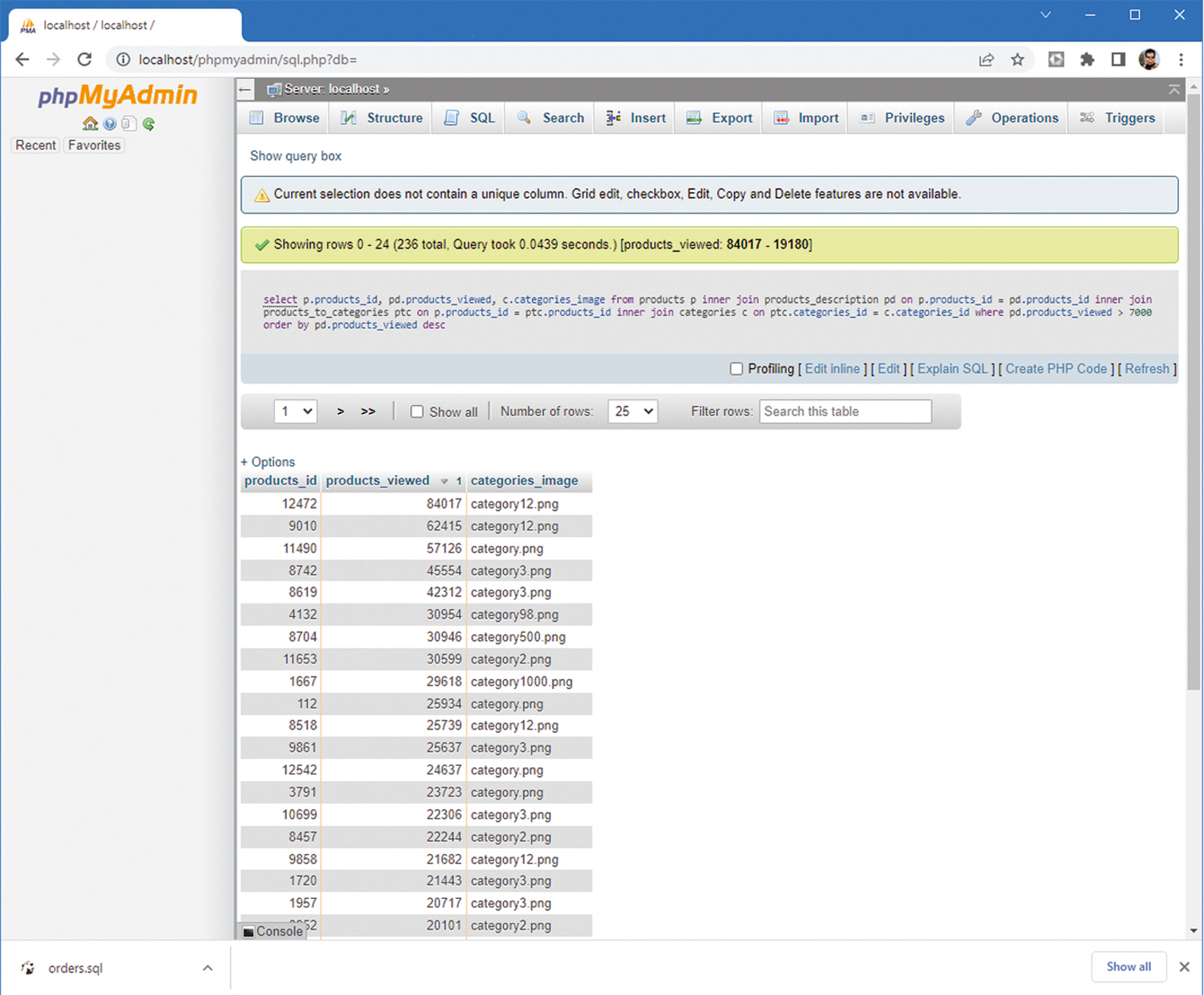
Primjer izvođenja SQL upita potrebno je dobro poznavati objekte i točno definirati što se želi dobiti iz baze podataka.
Najvažnije stvari povezane s korištenjem SQL naredbi najjednostavnije je prikazati na primjeru DQL naredbe SELECT. Evo jednog primjera sa spajanjem tablica:
select p.products_id, pd.products_viewed, c.categories_image
from products p
inner join products_description pd on p.products_id = pd.products_id
inner join products_to_categories ptc on p.products_id = ptc.products_id
inner join categories c on ptc.categories_id = c.categories_id
where pd.products_viewed > 7000
order by pd.products_viewed desc
Na temelju prethodnog primjera lako je vidljivo da je prilikom pripreme SQL ùpita:
Potrebno dobro poznavati postojeće objekte u bazi podataka, jer su podaci o pojedinom objektu iz stvarnog svijeta vrlo često podijeljeni u veći broj tablica.
Treba točno definirati što se sve želi dobiti iz baze podataka i na koji način.
Budući da su podaci u bazi podataka normalizirani, za dobivanje potrebnih podataka u pravilu je potrebno međusobno spojiti više tablica.
Već smo ranije spomenuli prednost baza dokumenata u odnosu na relacijske baze podataka u situacijama postojanja većeg broja nestrukturiranih podataka. Prethodna točka 3, kao što ćete vidjeti u nastavku teksta, predstavlja mjesto gdje graf baze podataka također mogu predstavljati bolje rješenje, ako se pri relacijskom modelu podataka pojavi potreba za mnogostrukim spajanjem različitih tablica. U određenim upitima može se pojaviti čak i zahtjev za većim brojem uključivanja iste tablice u upit pod različitim aliasima. U takvim slučajevima upit postavljen na graf baze podataka mnogo je jednostavniji za pisanje i razumijevanje od SQL upita.
Rezultati SQL upita vraćaju se kao skupina redova tablice (ili stupaca iz spojenih tablica), zbog čega ih je onda prilično jednostavno kopirati u druge relacijske baze podataka. ili spremiti u formate datoteka za prijenos/razmjenu podataka između različitih izvora kao što su CSV ili Excel tablice.
MQL
Kôd baza dokumenata SQL jezika nije pogodan za izravno korištenje, pa su se zato pojavili alternativni pristupi. MongoDB baza podataka, kao najpoznatiji i najrašireniji predstavnik baza dokumenata, koristi posebno razvijeni jezik upita od samog proizvođača baze podataka pod nazivom MQL (MongoDB’s Query Language). O čemu je riječ?
Budući da se dokumenti u MongoDB bazi čuvaju u JSON formatu (ili točnije u BSON – Binary JSON formatu zbog optimalnog zauzeća prostora i veće brzine obrade podataka), onda je nekako i logično da se upiti postavljaju u nečemu što također nalikuje JSON sintaksi.
Kako izgledaju MQL upiti najlakše je razumjeti na dva primjera prevođenja SQL upita u MQL sintaksu:
SQL:
----
SELECT COUNT(*) AS count
FROM person
SELECT band_name,
SUM(price) AS total
FROM albums
GROUP BY band_name
ORDER BY total
MQL:
----
db.person.aggregate( [
{
$group: {
_id: null,
count: { $sum: 1 }
}
}
] );
db.albums.aggregate( [
{
$group: {
_id: “$band_name”,
total: { $sum: “$price” }
}
},
{ $sort: { total: 1 } }
] );
Ako pogledate prateću sliku uz tekst s prikazom baze dokumenata o filmova nešto starijeg datuma, lako ćete primijetiti da je dio podataka (koji bi se u relacijskim bazama spremao u posebne tablice) u ovom slučaju jednostavno umetnut u osnovnu kolekciju dokumenata o filmovima. Naprimjer, žanrovi filmova, glumačka ekipa, scenaristi, osvojene nagrade i slično. Baza podataka o filmovima temeljena na dokumentima omogućava da u jednoj kolekciji budu obuhvaćeni svi mogući podaci o pojedinim filmovima, iako su neki od njih dostupni samo za dio filmova – npr. osvojene nagrade ili recenzije kritičara.
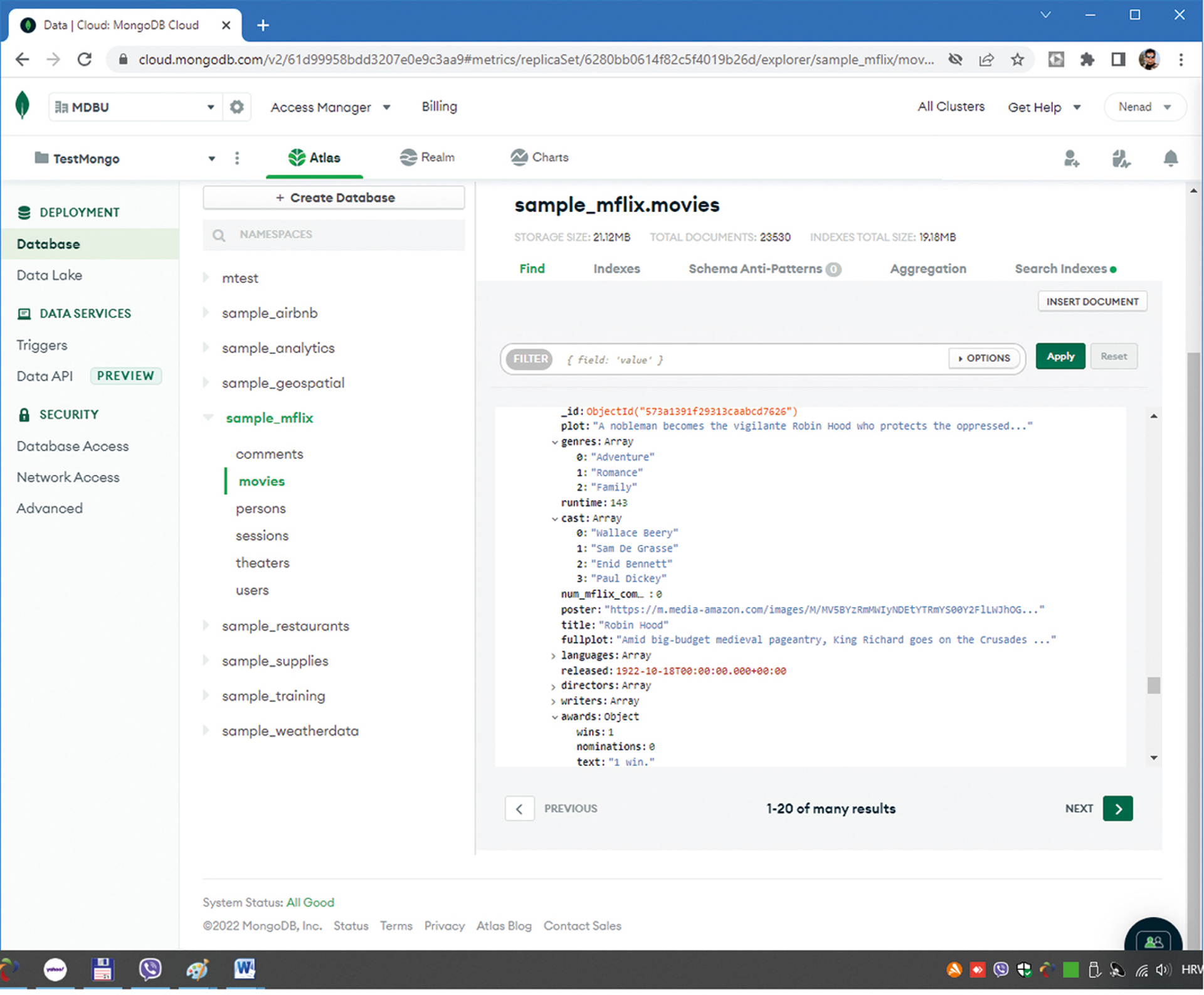
MongoDB Atlas: Primjer kako izgledaju podaci u cloud verziji baze dokumenata MongoDB.
Spomenimo usput da ovi podaci predstavljaju dio kolekcije demo podataka posebne cloud verzije baze podataka MongoDB. Korištenje cloud verzije ujedno predstavlja jedan od najjednostavnijih načina za upoznavanje s MongoDB bazom dokumenata, jer je veliki dio mogućnosti slobodno dostupan na web adresi: https://www.mongodb.com/atlas/database.
Budući da se u slučaju baza dokumenata velika većina međusobno povezanih podataka nalazi u okviru iste kolekcije dokumenata, a međusobno povezivanje različitih kolekcija u cilju dobivanja rezultata češće je izuzetak nego pravilo, za MQL upite vrijedi sljedeće:
MQL upite je jednostavnije pisati zato što ne trebate brinuti o međusobnom povezivanju velikog broja objekata da biste dobili željene podatke. Iako pri tome ipak morate znati sve atribute pojedine kolekcije dokumenata.
MongoDB Atlas: Usporedba mogućnosti besplatne verzije baze s verzijama koje se naplaćuju.
Istovremeno je teže pisati MQL upite zato što se u njima pojavljuje veliki broj različitih vrsta zagrada (čega nema ni izbliza toliko puno u SQL upitima), pa je to mjesto gdje je najlakše napraviti greške kod pripreme upita. Ipak se čovjek vremenom navikne na sve, pa tako i na zagrade, naročito uz pomoć odgovarajućih alata za pisanje upita.
Kao i kod SQL upita, treba točno napisati što se sve želi dobiti i na koji način.
Iako MongoDB ne zahtijeva kreiranje objekata poput kolekcija dokumenata prije njihova korištenja, postoji i dio naredbi koje odgovaraju SQL DDL naredbama (ako ništa drugo, potrebne su za uklanjanje postojećih kolekcija dokumenata).
Rezultati MQL upita vraćaju se također u sveprisutnom JSON obliku, što je pogodno za sve alate ili aplikacije koje prirodno razumiju takav format podataka. Naprimjer, različite mobilne aplikacije.
Spomenimo na ovom mjestu kako se za pristup bazama dokumenata mogu koristiti i drugi jezici upita (npr. unQL), ali je to već tema za neku drugu priliku.
Cypher
Ako se sad ponovo vratimo na problematiku čuvanja podataka u filmovima, za sada smo objasnili sljedeće: baza dokumenata predstavlja bolju alternativu za čuvanje različitih podataka o filmovima, pogotovo ako se ti podaci mogu međusobno poprilično razlikovati od filma do filma. Međutim što ako nas iz bilo kojeg razloga najviše zanimaju međusobni odnosi između osoba koje su sudjelovale u pripremi pojedinog filma, ako (kao autor teksta) zbilja volite gledati moderne filmove (bar neke žanrove), onda vam je sigurno poznato da pojedine osobe u jednom filmu mogu biti glumci, u drugom scenaristi, a u trećem režiseri (neki režiseri čak pišu i muziku za svoje vlastite filmove), dakle, vrlo složena situacija za modeliranje podataka u relacijskim bazama, ali i u bazama dokumenata.
Koliko podaci mogu biti složeni u graf bazama podataka vrlo jednostavno pokazuje prateća slika uz tekst preuzeta sa stranica poduzeća Cambridge Semantics. Na njoj je prikazano tek nekoliko osoba iz filmske industrije povezanih sa svima dobro poznatim oskarovcem Tomom Hanksom.
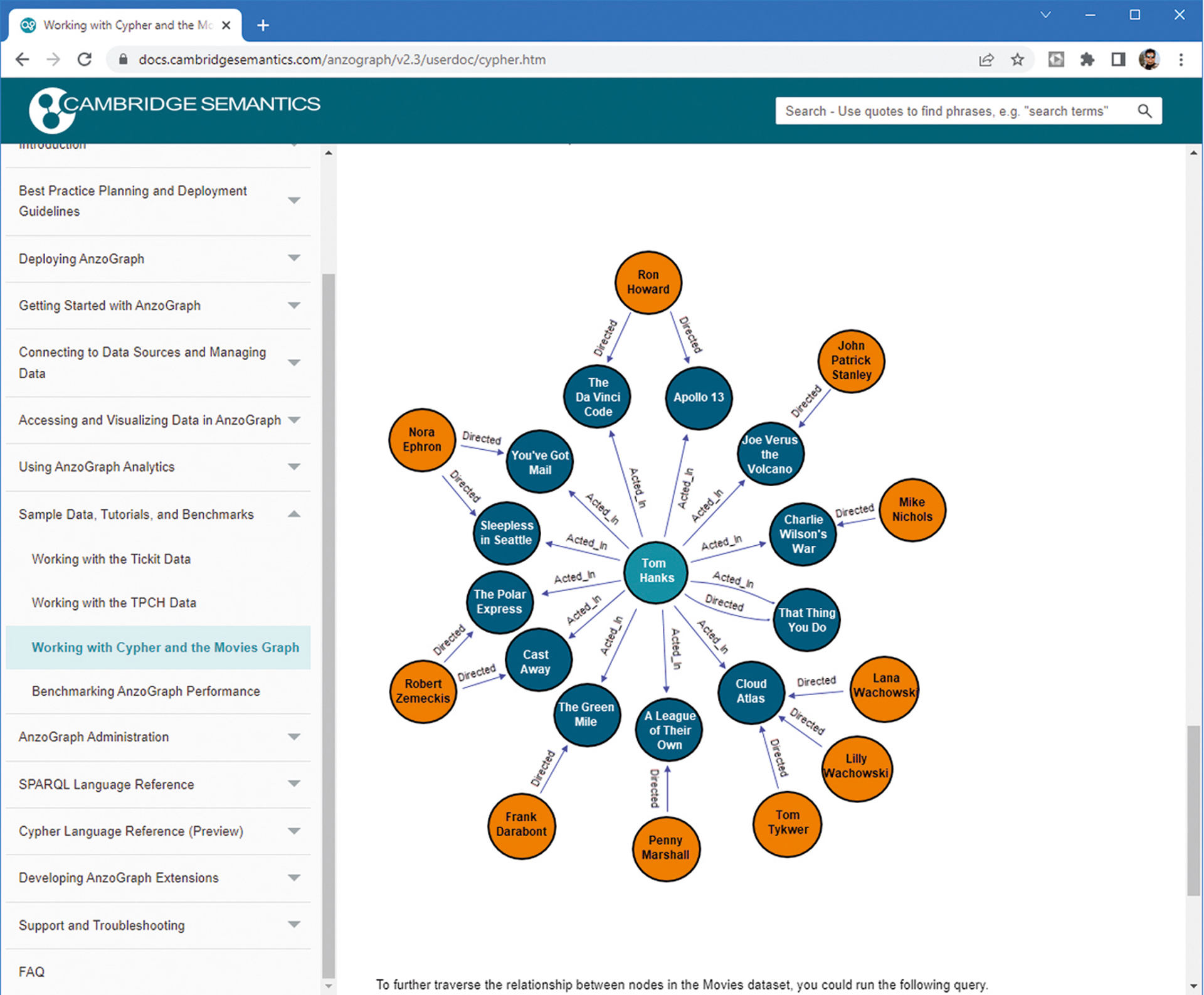
Cambridge Semantics: Primjer kako izgledaju podaci o filmovima u graf bazi podataka.
Tu u igru dolaze graf baze podataka, jer je kod njih ogroman broj međusobnih veza između nodova (u ovom slučaju osoba) nešto sasvim uobičajeno. Sasvim očekivano kod takve organizacije podataka u bazi ni SQL ni MQL ne mogu biti korišteni na odgovarajući način, pa zato u igru ulazi novi jezik upita Cypher. Riječ je o jeziku upita originalno razvijenom od proizvođača najpoznatije graf baze podataka Neo4j. Kasnije su ovaj jezik prihvatili i koriste ga i drugi proizvođači sličnih baza podataka. Na primjer i domaći Memgraph.
Najjednostavniji način na koji možete isprobavati Cypher naredbe je web adresa: https://neo4j.com/developer/cypher/querying/. Na njoj se nalazi čitav niz primjera naredbi čijim izvođenjem se odmah dobije i odgovarajući rezultat.
https://neo4j.com/: Najpoznatija graf baza podataka razvila je svoj jezik upita Cypher.
Koliko je Cypher (i ujedno graf baze podataka) pogodan za rad s različitim vezama među podacima najlakše je demonstrirati pomoću primjera jednakog upita pripremljenog na sličnim bazama u smislu spremljenih podataka (Neo4j i nekoj od relacijskih baza podataka). Primjer s dodatnim objašnjenjima je dostupan na adresi: https://neo4j.com/blog/sql-vs-cypher-query-languages.
Cypher upit (izgleda prilično kratko i jednostavno):
MATCH (u:Customer {customer_id:’customer-one’})-[:BOUGHT]->(p:Product)<- [:BOUGHT]-(peer:Customer)-[:BOUGHT]->(reco:Product)
WHERE not (u)-[:BOUGHT]->(reco)
RETURN reco as Recommendation, count(*) as Frequency
ORDER BY Frequency DESC LIMIT 5;
ali je zato slični SQL upit „malo kompliciraniji“, zar ne?
SELECT product.product_name as Recommendation, count(1) as Frequency
FROM product, customer_product_mapping, (SELECT cpm3.product_id, cpm3.customer_id
FROM Customer_product_mapping cpm, Customer_product_mapping cpm2, Customer_product_mapping cpm3
WHERE cpm.customer_id = ‘customer-one’
and cpm.product_id = cpm2.product_id
and cpm2.customer_id != ‘customer-one’
and cpm3.customer_id = cpm2.customer_id
and cpm3.product_id not in (select distinct product_id
FROM Customer_product_mapping cpm
WHERE cpm.customer_id = ‘customer-one’)
) recommended_products
WHERE customer_product_mapping.product_id = product.product_id
and customer_product_mapping.product_id in recommended_products.product_id
and customer_product_mapping.customer_id = recommended_products.customer_id
GROUP BY product.product_name
ORDER BY Frequency desc
Neo4j Aura DB baza dostupna je za slobodno korištenje u cloudu.
Naravno opis postavljanja upita na bazu Cypher omogućava i pripremu objekata u bazi (ranije spomenutih čvorova, veza i svojstava). Na primjer:
MATCH
(a:Person),
(b:Person)
WHERE a.name = ‘A’ AND b.name = ‘B’
CREATE (a)-[r:RELTYPE {name: a.name + ‘<->’ + b.name}]->(b)
RETURN type(r), r.name
Za kraj
Ako ste do sada samo čuli za i/ili u praksi koristili relacijske baze podataka, možda čitanjem ovog teksta dobijete ideju kako bi za neki problem iz prakse bilo bolje iskoristiti alternativni pristup u modeliranju podataka i postavljanju upita. Što (budimo realni) nije uvijek jednostavno primijeniti u stvarnosti. Pogotovo ako radite u poduzeću koje godinama koristi isključivo relacijske baze podataka i već je investiralo ogromne količine vremena i sredstava u razvoj na njima temeljenih aplikacija. Međutim, ako ste startup koji kreće ispočetka, onda primjena drugačijeg pristupa u rukovanju podacima (ako to ima smisla) vjerojatno i nije toliko komplicirana, a može dati bolje rezultate nego korištenje relacijskih baza podataka.