






Opće je poznato da se u današnje vrijeme ogromna količina podataka priprema i prikazuje u različitim oblicima web rješenja, i da se istovremeno ti isti podaci prikupljaju za korištenje od strane drugih korisnika, tvrtki ili AI sustava.
U ovom tekstu pozabavit ćemo se drugim korakom, to jest prikupljanjem postojećih podataka s web stranica, s naglaskom na tehničku stranu. Različite pravne finese povezane s prikupljanjem podataka prelaze okvire ovog teksta, iako ćemo u posebnom izdvojenom dijelu teksta spomenuti najvažnije činjenice povezane s tim dijelom.
Web crawling vs web scraping
Razjasnimo prvo oba pojma iz naslova. Riječ je o različitim stvarima, ali se one u praksi često međusobno miješaju.
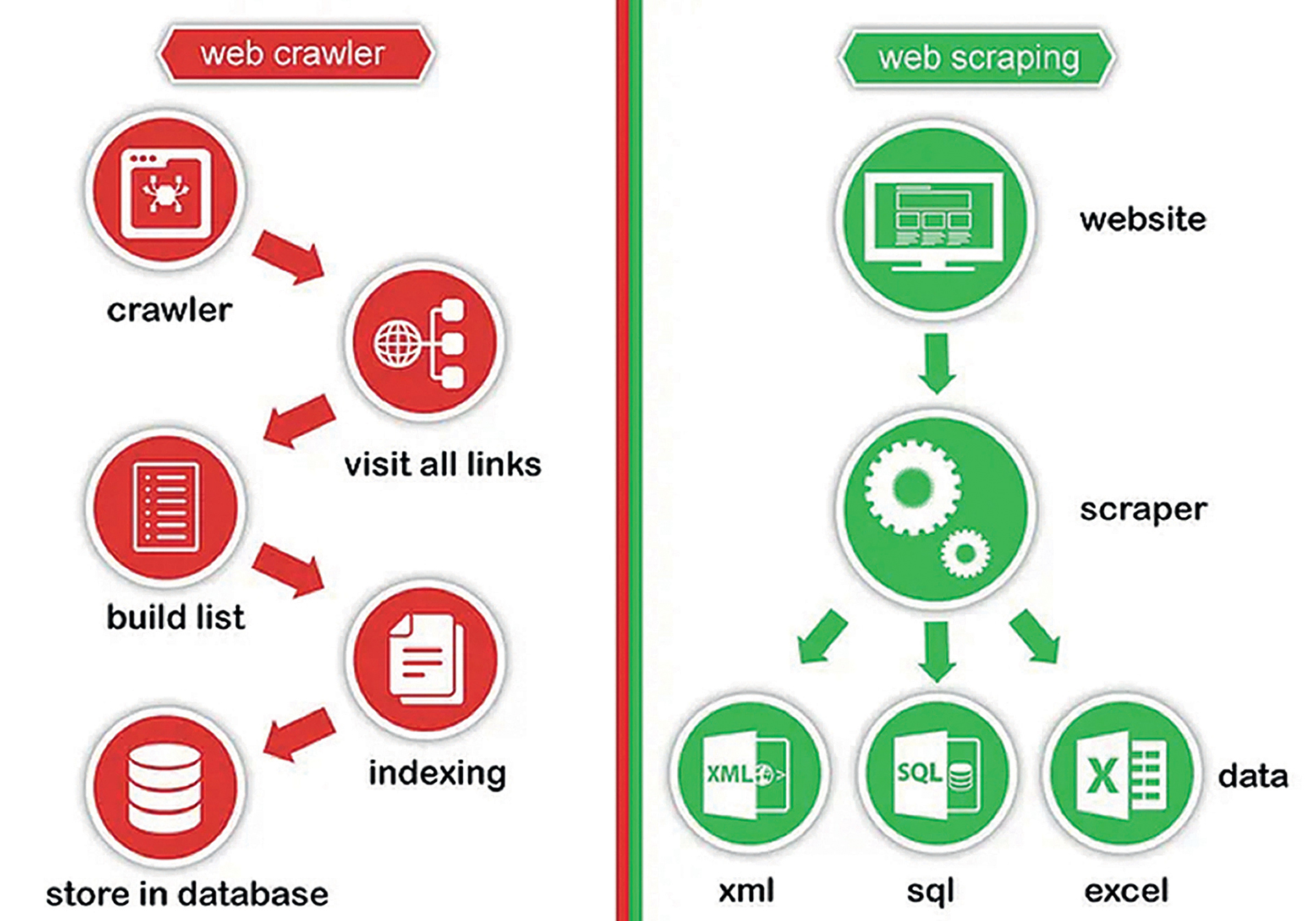
Web crawling koristi se za analizu neke web lokacije kako bi se saznalo koje sve stranice postoje na toj lokaciji. Kao rezultat izvođenja dobije se svojevrsna karta web lokacije. U konačnici se tako prikupljeni podaci spremaju u odgovarajuće spremište – neki od standardnih formata datoteka (kao što su Excel ili CSV) ili neku od baza podataka, kako bi se ti podaci mogli ponovo koristiti kad nam to zatreba.
Tehnički se u automatiziranim okruženjima (kao što su različite tražilice) postupak implementira pomoću automatiziranog bota („spidera“ ili „pauka“), koji bi tijekom analize web lokacije trebao obavezno konzultirati sadržaj datoteke robots.txt. Takvom implementacijom može se spriječiti pristup nedozvoljenim stranicama (definiranim od strane kreatora sadržaja), odnosno stranicama bez neke posebne važnosti za rezultate (pomoćne, setup i slične stranice) kako se na njih ne bi nepotrebno trošili resursi kod analize web lokacije.
Tijekom postupka web crawlinga ne izvodi se nikakva posebna analiza sadržaja pojedine stranice, nego je cilj prije svega napraviti popis relevantnih stranica na ciljanoj web lokaciji.
Neki od hrvatskih izraza za ovaj postupak (manje ili više prihvaćenih u praksi) su sustavno pretraživanje weba, indeksiranje weba i pretraživanje weba. U nastavku teksta držat ćemo se originalnog naziva.
Web crawling u praksi koriste različite tražilice kao što su Google ili Bing kako bi mogle krajnjim korisnicima prikazati rezultate zadanog pretraživanja. Druga vrsta korisnika ovog postupka su različiti agregatori vijesti, kako bi na jednom mjestu mogli prikazati prikupljene vijesti o određenom području s različitih web lokacija. Na kraju, u popis korisnika treba svakako dodati SEO stručnjake, jer im web crawling pomaže pronaći eventualne neispravne veze prema stranicama na analiziranoj web lokaciji, odnosno provjeriti kako neku web lokaciju doista vide poznate tražilice.
Web scraping postupak zadužen je za izdvajanje detaljnih podataka s pojedine web stranice. Kao i kod crawlinga, ti podaci se nakon pripreme spremaju u neko spremište (najčešće neku bazu podataka).
I ovdje postoji nekoliko hrvatskih prijevoda za sam postupak, kao što su struganje weba, automatizirano prikupljanje ili ekstrakcija podataka s weba, web prikupljanje podataka, i slično. Kao i u slučaju crawlinga, u nastavku teksta koristit ćemo originalni engleski pojam. Ipak ćemo tu i tamo upotrijebiti i pojam „struganje“, jer nam je baš fora!
Korisnici web scrapinga su različiti portali za međusobno uspoređivanje cijena (i drugih karakteristika) istih proizvoda ili usluga na različitim web lokacijama, analitičari, marketinški stručnjaci i znanstvenici zbog različitih oblika istraživanja tržišta, različitih trendova ili pisanja znanstvenih/stručnih radova, te na kraju AI orijentirane tvrtke kako bi takvim podacima mogle nadopuniti svoje AI modele.
U praksi se oba postupka često koriste u međusobnoj suradnji. Pomoću postupka web crawlinga priprema se popis stranica koje nakon toga treba detaljnije „postrugati“ postupkom web scrapinga.
Web crawling i web scraping : Razlike između ova dva postupka
Kako se oba postupka koriste u AI modelima
Današnji AI (LLM) modeli zapravo ne bi mogli uopće dobro djelovati bez intenzivnog oslanjanja na oba postupka. Velike AI tvrtke (OpenAI i slične) prvo u fazi treniranja modela vrlo intenzivno koriste web crawling da bi njihovi modeli bili „upućeni“ u cijeli javno dostupni web sadržaj. To obuhvaća pretraživanje različitih portala s vijestima, Wikipedije, različitih programerskih foruma (ali i foruma za ostala zanimanja), znanstvenih biblioteka i tako dalje.
Na temelju tako pripremljene „strukture cjelokupnog weba“ sa odgovarajućih stranica se scrapingom izdvajaju samo čisti tekstualni podaci, a istovremeno uklanjaju brojni dodatni elementi kao što su reklame, navigacijske strukture na stranici i slično. Osim automatskih tehnika na čišćenju podataka još uvijek radi i veliki broj ljudi, kako bi se na najtočniji mogući način pročistilo potencijalno smeće u podacima. Najčešće je riječ o online poslovima koji se obavljaju s različitih lokacija iz svijeta, uključujući vrlo često one s vrlo malim primanjima po stanovniku. O čemu su već snimljeni vrlo zanimljivi dokumentarni filmovi, pa ih možete pronaći i pogledati, ako to želite. Na temelju tako očišćenih podataka izvodi se učenje LLM modela.
U fazi korištenja, to jest postavljanja upita, AI model prvo u strukturi weba pronalazi najvažnije linkove za odgovor na postavljeno pitanje (to je ona animacija koju većina modela pokazuje dok „razmišlja“ o odgovoru), a onda se na najrelevantnijim stranicama izvodi scraping, te u konačnici integracija podataka prije prikaza korisniku.
Zašto bi netko još uvijek samostalno koristio oba procesa?
Web crawling i web scraping su pojmovi koji su u IT svijetu prisutni mnogo duže od AI LLM modela, što znači da se mogu koristiti samostalno bez ikakve veze s AI sustavima. Pitanje koje se nameće samo po sebi je zašto bi netko i dalje koristio svoje vlastite web crawling i web scraping sustave kad „AI sve to zamjenjuje“?
Prvi i najjednostavniji razlog je „nasljeđe“. Ako ste svoja crawling/scraping rješenja počeli razvijati i koristiti godinama prije AI modela, onda u njima već imate vrijedne podatke iz prošlosti za koje ne možete biti sigurni da će ih prikupiti neki AI model. Sasvim dovoljan razlog da i dalje održavate te nadograđujete svoja rješenja.
Drugi razlog su troškovi. Vaši vlastiti modeli za obradu točno određenog segmenta podataka mogu raditi mnogo brže od AI modela i zahtijevati prilično jeftino okruženje za rad. U konačnici to može ispasti jeftinije nego plaćanje za kontinuirano, komercijalno korištenje nekog AI modela.
Treće, AI modeli rade na principu vjerojatnosti, što znači da ne moraju uvijek dati potpuno jednaki rezultat. U slučaju kad se zahtijeva potpuna preciznost u rukovanju podacima, vlastito rješenje može u tom smislu dati bolje i točnije rezultate.
Četvrto, vlastitim rješenjem osiguravate privatnost i sigurnost podataka, što može biti ključan faktor u situacijama kad ne želite da neki osjetljiv podatak završi na krivom mjestu.
Budući da na temelju prethodno navedenog i dalje postoji razlog za zaobilaženje AI modela kod prikupljanja podataka s weba, objasnimo kako se mogu samostalno pripremiti postupci web crawlinga i web scrapinga. U osnovi za to postoje dva pristupa:
- Razvoj rješenja za programere
- Razvoj rješenja za „neprogramere“ (ili za one koji nešto slabije programiraju)
crawling.py: Primjer Python koda za crawling i rezultati izvođenja
Rješenje za programere
I web crawling i web scraping mogu se kvalitetno napraviti u različitim programskim jezicima. Veliku pomoć pri tome obično predstavljaju dodatne biblioteke za izvođenje takvih postupaka, ako su dostupne za izabrani programski jezik. Budući da Python danas predstavlja svojevrsni „lingua franca“ na brojnim IT područjima, demonstrirat ćemo primjere upravo u tom jeziku.
Za oba primjera u Pythonu koristit ćemo dodatnu biblioteku Beautiful Soup. Riječ je o posebno pripremljenoj biblioteci za što jednostavnije pisanje programskog koda za izdvajanje podataka s web stranica. Također, u oba slučaja potrebna nam je i biblioteka request za slanje HTTP zahtjeva prema serveru.
U sljedećim primjerima koristit ćemo najjednostavniji mogući oblik programskog koda koji izvodi web crawling i web scraping na web lokaciji https://www.vidi.hr/. Dobivene rezultate nakon toga sprema u odgovarajuće tekstualne datoteke (crawling.txt i scraping.txt). U praksi su ovakvi primjeri puno složeniji u slučajevima kad podatke želite spremiti u bazu podataka, ili posebno „strugati“ i razvrstavati različite HTML elemente na stranici. Da ne zaboravimo da bi kod ovakvih postupaka trebalo obavezno uzeti u obzir i sadržaj datoteke robots.txt, što ćemo u našim pojednostavljenim primjerima u potpunosti ignorirati.
Slijede primjeri Python koda za oba postupka zajedno s kratkim objašnjenjem te primjerom dijela rezultata zapisanog u tekstualne datoteke s rezultatima.
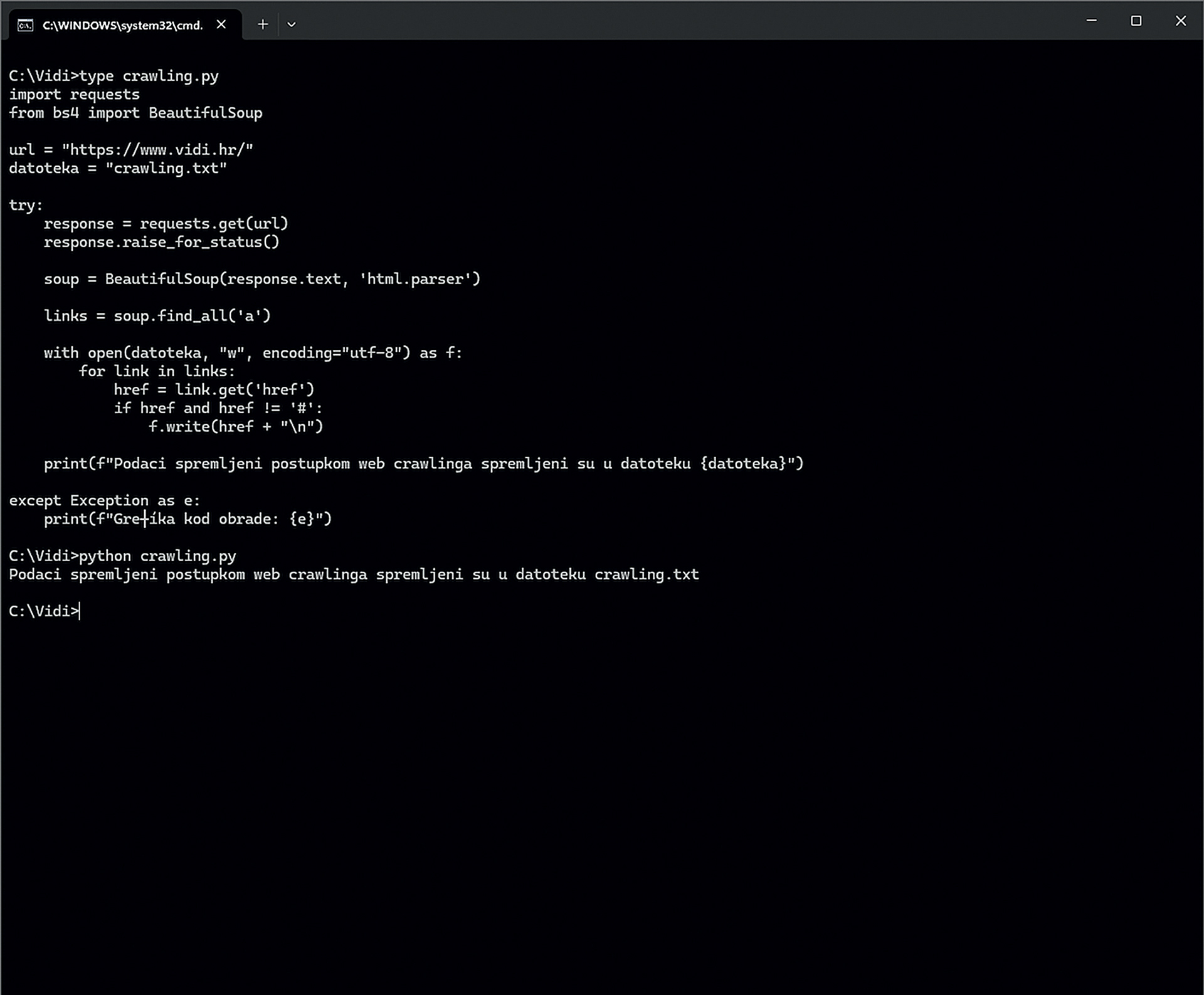
crawling.py
import requests
from bs4 import BeautifulSoup
url = “https://www.vidi.hr/”
datoteka = “crawling.txt”
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, ‘html.parser’)
links = soup.find_all(‘a’)
with open(datoteka, “w”, encoding=”utf-8”) as f:
for link in links:
href = link.get(‘href’)
if href and href != ‘#’:
f.write(href + “\n”)
print(f”Podaci spremljeni postupkom web crawlinga spremljeni su u datoteku {datoteka}”)
except Exception as e:
print(f”Greška kod obrade: {e}”)
Nakon definiranja web lokacije koja će se analizirati i datoteke za spremanje rezultata, šalje se upit prema serveru. U vraćenim rezultatima (pod uvjetom da sve prođe dobro) traže se i izdvajaju svi linkovi (odnosno „<a>“ elementi). Dobiveni rezultati spremaju se u tekstualnu datoteku uz malo „čišćenje“ linkova koji se sastoje isključivo od znaka „#“. Na kraju se prikazuje odgovarajuća obavijest da je završila obrada. Sve skupa je „zatvoreno“ u strukturu za obradu pogrešaka kako bi se spriječila nepredviđena „pucanja“ programa tijekom izvođenja.
crawling.txt
https://baneri.vidi.hr/www/delivery/ck.php?n=a7b7661b&cb=INSERT_RANDOM_NUMBER_HERE
https://baneri.vidi.hr/www/delivery/ck.php?n=ae3cce1b&cb=INSERT_RANDOM_NUMBER_HERE
/
/Non-Tech/Hrvatska/Jeremy-Wang-o-planovima-BYD-a-za-Europu
/Non-Tech/Hrvatska/Jeremy-Wang-o-planovima-BYD-a-za-Europu
/Non-Tech/Hrvatska/Sinisa-Krajnovic-o-buducnosti-telekom-industrija
/Non-Tech/Hrvatska/Sinisa-Krajnovic-o-buducnosti-telekom-industrija
/Non-Tech/Hrvatska/Stjepan-Sucic-o-trendovima-za-2026
/Non-Tech/Hrvatska/Stjepan-Sucic-o-trendovima-za-2026
/Non-Tech/Hrvatska/Intervju-Vedran-Bajer
/Non-Tech/Hrvatska/Intervju-Vedran-Bajer
/Lifestyle/Business-3.0/Lana-Dinic-o-buducnosti-inovacija
/Lifestyle/Business-3.0/Lana-Dinic-o-buducnosti-inovacija
https://www.mobil.hr/zanimljivosti/samsung-obecao-cetiri-godine-softverske-podrske-za-sve-telefone-iz-2019-godine-i-one-novije/
https://www.pcplay.hr
http://vidipedija.com/~vidipedi/index.php?title=AMD
https://forum.vidi.hr/
/Vidi-grupa/VIDI-Lab/Samsung-Galaxy-S25-Ultra
https://www.vidilab.com/hardver/mobil/pametni-telefon/7513-samsung-galaxy-s25-ultra
/Vidi-grupa/VIDI-Auto/Clio-s-trona-skinuo-Octaviju
http://www.vidiauto.com/Novosti/Autobiz/Clio-s-trona-skinuo-Octaviju
/rss/feed/vidi
https://www.facebook.com/pages/VIDI/96255505273
https://twitter.com/vidimag
/
/Non-Tech
/Non-Tech/Svijet/Treniranje-AI-modela-podacima-s-ukrajinskog-bojista
/Non-Tech/Svijet/Treniranje-AI-modela-podacima-s-ukrajinskog-bojista
/Non-Tech/Svijet/Meta-kupuje-drustvenu-mrezu-za-AI-botove
/Non-Tech/Svijet/Meta-kupuje-drustvenu-mrezu-za-AI-botove
/Non-Tech/Hrvatska/VIDEO-Hrvatska-igra-prikupila-novac-u-samo-25-minuta
/Non-Tech/Hrvatska/VIDEO-Hrvatska-igra-prikupila-novac-u-samo-25-minuta
/Non-Tech/Svijet/VIDEO-Netflix-kupuje-AI-startup-Bena-Afflecka
/Non-Tech/Svijet/VIDEO-Netflix-kupuje-AI-startup-Bena-Afflecka
/Non-Tech/Svijet/Burger-King-ce-koristiti-AI-za-kontrolu-zaposlenika
/Non-Tech/Svijet/Burger-King-ce-koristiti-AI-za-kontrolu-zaposlenika
/Non-Tech/Svijet/NATO-odobrio-iPhone-i-iPad-za-sigurnu-uporabu
/Non-Tech/Svijet/NATO-odobrio-iPhone-i-iPad-za-sigurnu-uporabu
…
scraping.py: Primjer Python koda za scraping i rezultati izvođenja
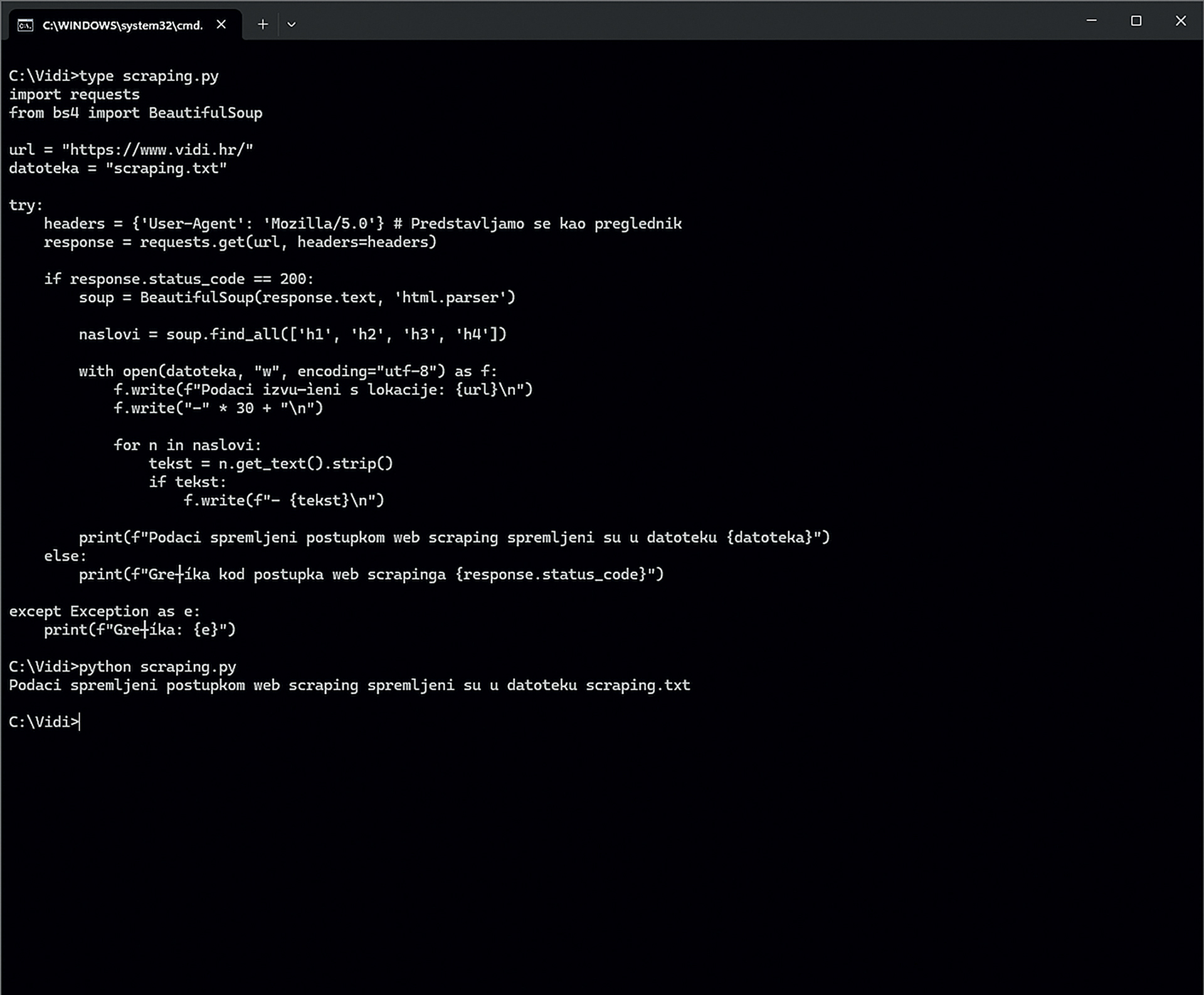
scraping.py
import requests
from bs4 import BeautifulSoup
url = “https://www.vidi.hr/”
datoteka = “scraping.txt”
try:
headers = {‘User-Agent’: ‘Mozilla/5.0’}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, ‘html.parser’)
naslovi = soup.find_all([‘h1’, ‘h2’, ‘h3’, ‘h4’])
with open(datoteka, “w”, encoding=”utf-8”) as f:
f.write(f”Podaci izvučeni s lokacije: {url}\n”)
f.write(“-” * 30 + “\n”)
for n in naslovi:
tekst = n.get_text().strip()
if tekst:
f.write(f”- {tekst}\n”)
print(f”Podaci spremljeni postupkom web scrapinga spremljeni su u datoteku {datoteka}”)
else:
print(f”Greška kod postupka web scrapinga {response.status_code}”)
except Exception as e:
print(f”Greška: {e}”)
Ovaj primjer ima dosta sličnosti s prethodnim u pogledu pristupa serveru, spremanja sadržaja u tekstualnu datoteku, poruka korisniku i obrade pogrešaka. Najveća razlika je u načinu pristupa HTML elementima koji nas zanimaju na stranici. U ovom pojednostavljenom primjeru su to elementi od <h1> do <h4>, pa se zato samo oni izdvajaju sa stranice i spremaju u tekstualnu datoteku.
Octoparse: Jedan od najpopularnijih alata za web scraping za „neprogramere“
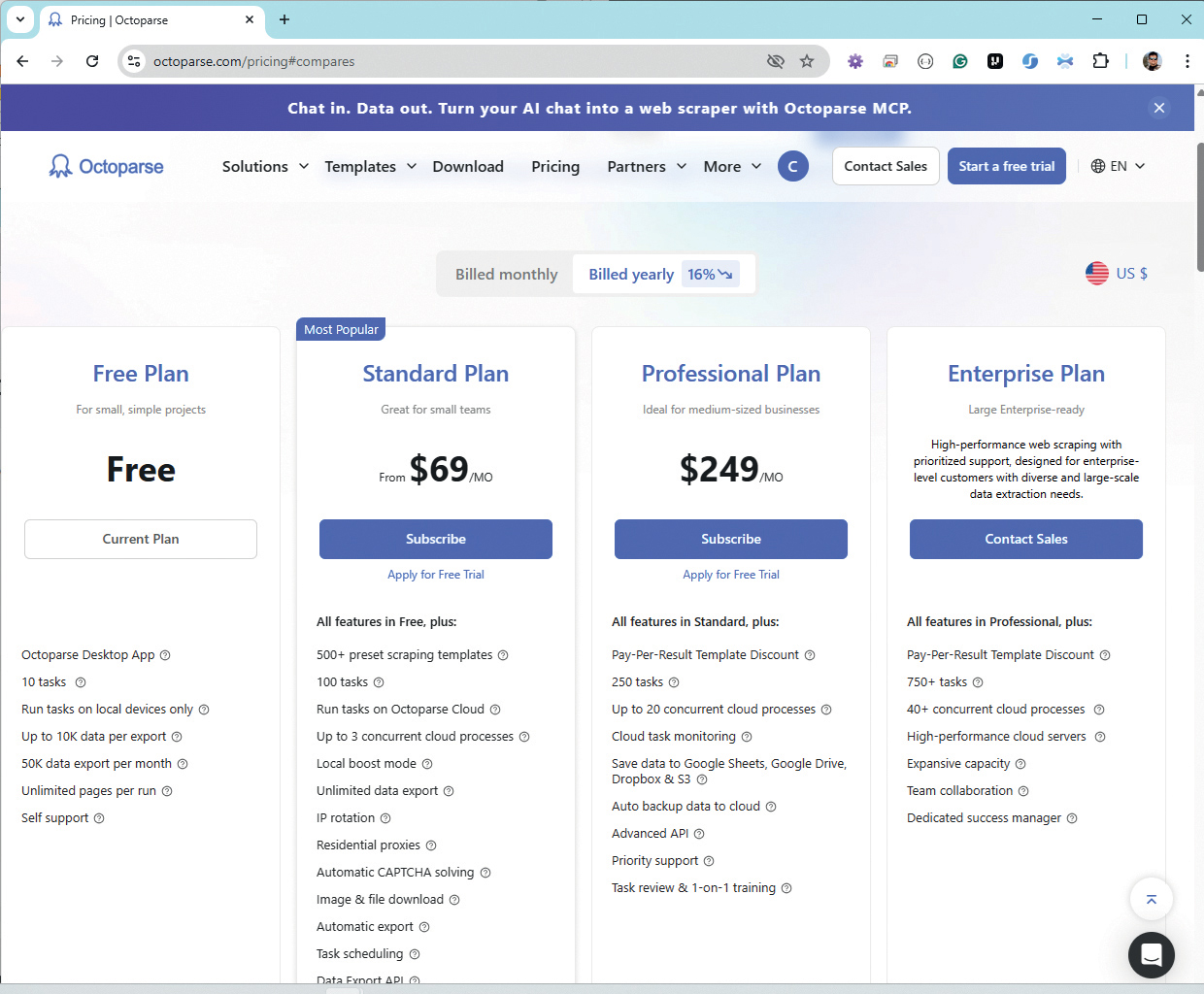
Komercijalno korištenje: Postoji nekoliko oblika s plaćanjem na mjesečnoj razini
scraping.txt
Podaci izvučeni s lokacije: https://www.vidi.hr/
------------------------------
- Jeremy Wang o planovima BYD-a za Europu
- Siniša Krajnović o budućnosti telekom industrija
- Stjepan Sučić o trendovima za 2026.
- Intervju: Vedran Bajer
- Lana Dinić o budućnosti inovacija
- Mobil.hr
- PC Play.hr
- Vidipedija
- Forum
- VIDI Lab
- VIDI Auto
- NOVOSTI
- PODKATEGORIJE
- NOVOSTI
- PODKATEGORIJE
- NOVOSTI
- PODKATEGORIJE
- NOVOSTI
- NOVOSTI
- NOVOSTI
- PODKATEGORIJE
- NOVOSTI
- PODKATEGORIJE
- Francuska gradi svoju zlatnu kupolu
- Povezanost Parkinsonove bolesti s krvnim stanicama
- Treniranje AI modela podacima s ukrajinskog bojišta
- VIDEO: Pogledajte prvi film s robotom u povijesti
- Meta razvija 4 nova čipa za AI
- Novac kakav poznajemo uskoro nestaje
- Infobip otvara novi ured u Osijeku
- Novi Xbox će pokretati AMD-ov SoC
- VIDI forum
- Anketa
- Burger King će koristiti AI za kontrolu zaposlenika
- NATO odobrio iPhone i iPad za sigurnu uporabu
- Amazon započinje testiranje robotaksija
- VIDEO: Gemini vam sada može kreirati glazbu
- Umjetna inteligencija voli nuklearne ratove
…
To što prethodni primjeri pokazuju koliko je jednostavno koristiti Python za oba zadatka, ne znači da drugi programski jezici nisu dobar izbor, pogotovo ako imate odgovarajuće biblioteke vlastitog koda zaostale iz prethodnih projekata. Na primjer, autor teksta za slične projekte u pravilu radije bira Visual Studio, ili preciznije Visual C#.
Nakon godina i godina programiranja u navedenim alatima (uključujući crawling i scraping projekte) ne samo da ima gotove rutine za pretraživanje web lokacija i „struganje informacija“ sa stranica, nego također čitav niz biblioteka za spremanje sadržaja u različite formate zapisa (od običnih tekstualnih ili Excel datoteka do relacijskih baza podataka ili baza dokumenata). Rad na novom scraping projektu je u takvim slučajevima puno brži, pogotovo ako ne zahtijeva velike modifikacije u odnosu na stara rješenja. Zapravo, u takvim slučajevima se puno više vremena potroši na analizu nove strukture stranice nego na samo programiranje i testiranje.
Još jedan od razloga zašto autor teksta voli koristiti Visual Studio u scraping projektima je mogućnost preuzimanja dinamičkog sadržaja web stranica. U prethodnom Python primjeru programski kod je jednostavno „sastrugao“ postojeće podatke s trenutačnog sadržaja stranice. Međutim, na dijelu web stranica to nije baš tako jednostavno. U određenim web rješenjima korisnik prvo treba kliknuti na neki link/gumb da bi se na stranici pojavile dodatne informacije.
Windows aplikacija: Nudi unaprijed pripremljen scraping za veliki broj popularnih web lokacija
Korištenje Visual Studija i unutar njega Microsoftovog dodatnog elementa (koji se može besplatno koristiti) Microsoft Edge WebView2 (https://developer.microsoft.com/en-us/microsoft-edge/webview2/?form=MA13LH) omogućava baš takav scraping. Kako se to može implementirati u vlastitim projektima?
Prvo se u projektu na Windows formu postavi spomenuta kontrola čime se zapravo dobiva pravi Microsoft Edge preglednik zatvoren unutar vlastite aplikacije.
Nakon toga možemo takvim preglednikom uz pomoć kombinacije Visual C#/JavaScript koda simulirati željene operacije baš kao da ih izvodi sam korisnik (klikovi i slično).
Kad se kao rezultat korisnikove simulirane akcije pojave podaci koji nam trebaju, izvodimo njihov dodatni scraping i spremanje u bazu.
Detaljnije objašnjenje cijelog mehanizma prelazi okvire ovog teksta, ali ćemo korisnicima koje to zanima u nastavku navesti dio koda kao ideju za razvoj sličnih vlastitih tehnika.
Probno korištenje: Octoparse možete koristiti besplatno u periodu od 14 dana
string html = await webView21.CoreWebView2.ExecuteScriptAsync(“document.documentElement.outerHTML”);
html = System.Text.RegularExpressions.Regex.Unescape(html);
html = html.Substring(1, html.Length - 2);
rtbSource.Text = html;
string jscode = @”
var selects = document.querySelectorAll(‘select’);
selects.forEach(function(select) {
if (select.options.length > 0) {
var firstValue = select.options[0].value;
if (firstValue == ‘30’) {
select.value = ‘xx’;
select.dispatchEvent(new Event(‘change’, { bubbles: true }));
}
}
});
“;
jscode = jscode.Replace(“xx”, getPeriod());
await webView21.CoreWebView2.ExecuteScriptAsync(jscode);
System.Windows.Forms.Application.DoEvents(); Thread.Sleep(1000);
string script = $@”
var buttons = document.querySelectorAll(‘button, input[type=button], input[type=submit]’);
for (var i = 0; i < buttons.length; i++) {{
if (buttons[i].innerText.trim() === ‘Download Historical Data’
|| buttons[i].value.trim() === ‘Download Historical Data’) {{
buttons[i].click();
break;
}}
}}
“;
await webView21.ExecuteScriptAsync(script);
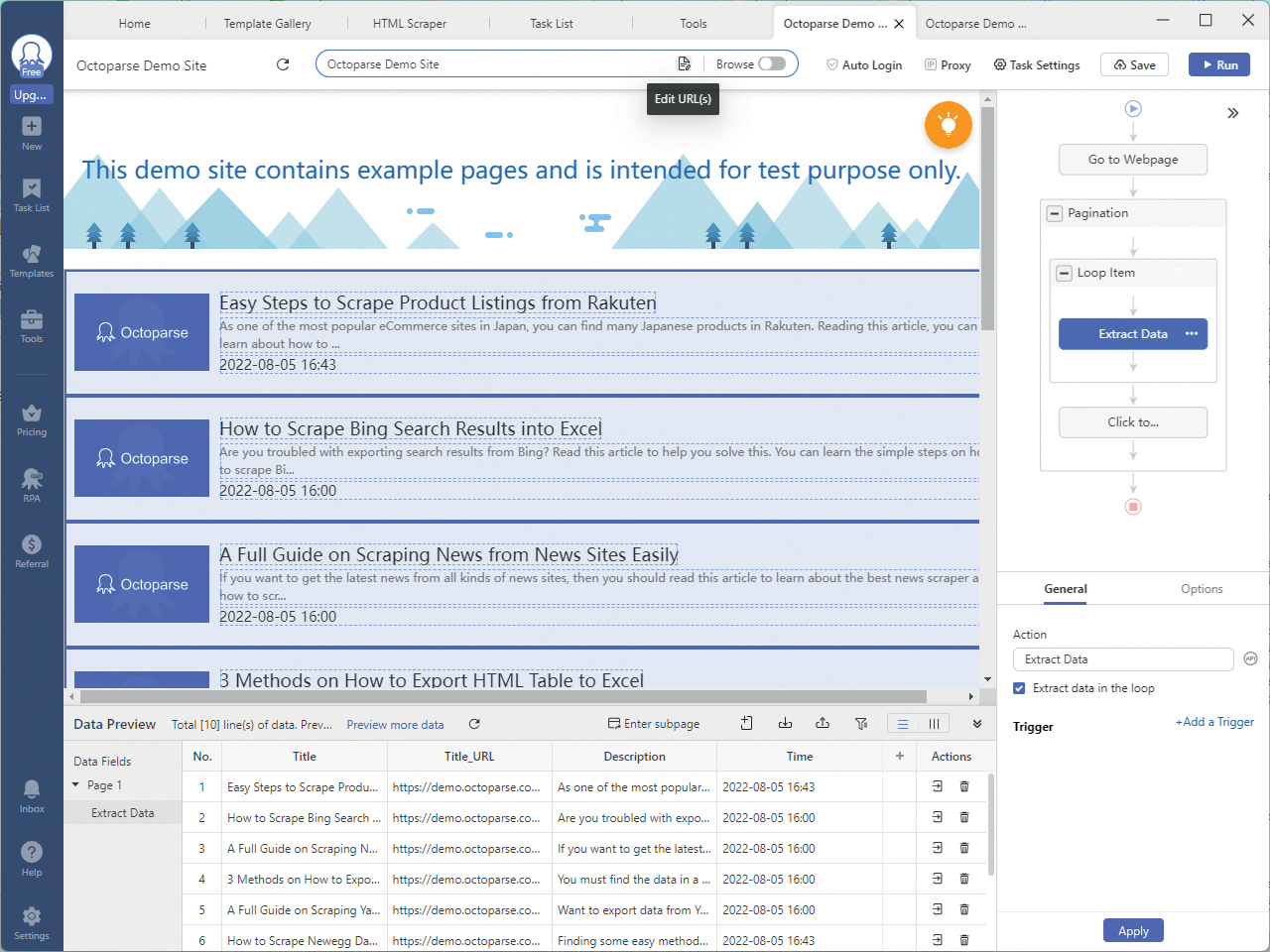
Octoparse Demo Site: Koristi se za demonstraciju mogućnosti alata.
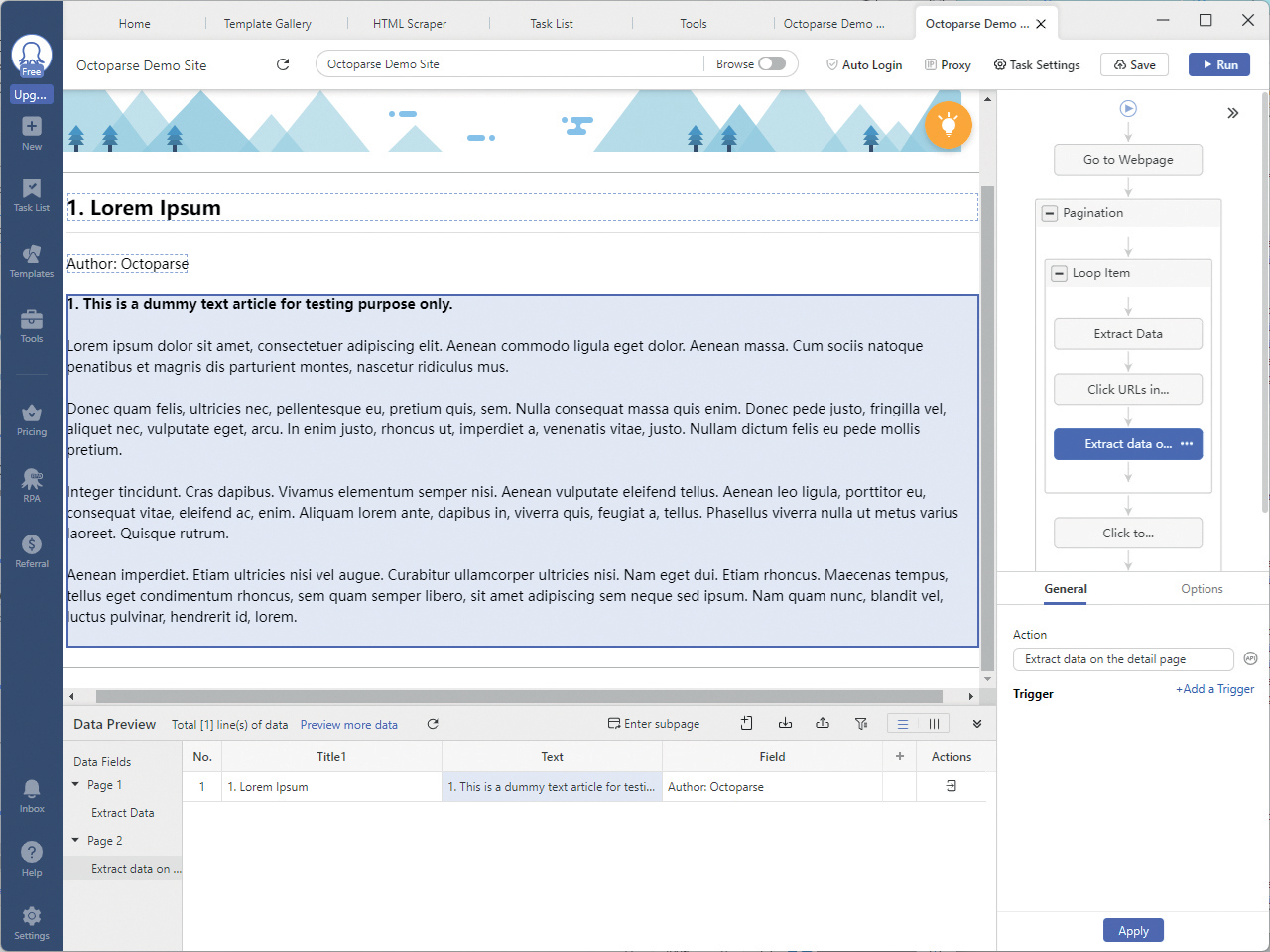
Octoparse Demo Site: Definiranje dodatnih postavki u projektu
Što radi prethodni dio koda (izvađen iz velikog projekta) koji zapravo predstavlja kombinaciju Visual C# i JavaScript koda? Ako želimo biti precizniji, Visual C# zapravo šalje ranije spomenutoj Microsoft Edge kontroli upute za simuliranje korisnikovog djelovanja na web stranici, napisane u JavaScriptu. To jednostavno mora biti tako, jer Microsoft Edge kontrola ne razumije Visual C#, ali zato dobro „sluša“ što od nje zahtijeva JavaScript. Visual C# nakon toga može ponovo otkriti što se promijenilo na stranici i nastaviti odrađivati svoj dio scraping zadatka.
U ovom konkretnom slučaju na web stranici je postojao gumb za preuzimanje podataka Download Historical Data, ali se sami podaci zapravo ne vide na samoj web stranici, pa zato nije ni moguć izravni scraping. Na istoj stranici nalazi se dodatni HTML element Select pomoću kojeg korisnik može birati za koji period su mu potrebni podaci, a tek onda izabrati njihovo preuzimanje.
Prethodna kombinacija programskog koda radi upravo to isto što bi napravio korisnik. Prvo izabere željeni period (koji dolazi kao ulazni parametar u ovaj dio koda), malo pričeka da se web stranica obnovi kao posljedica prethodne akcije, a onda simulira klik na gumb za preuzimanje podataka.
Rješenje za „one druge“
Na današnjem stupnju razvoja IT tehnologije gotovo uvijek postoji drugačiji pristup za „one druge“. Osobe koje ne znaju, ne žele ili nemaju vremena programirati. U tom slučaju treba pronaći alat koji izvodi iste operacije i daje jednake (ili bar slične) rezultate, kao kad bi istu stvar odradio dobar programer.
Jedno od najpopularnijih rješenja iz ove grupe je alat Octoparse. Uz pomoć takvog alata možete koristiti vizualni pristup kod definiranja dijelova stranice koje želite sastrugati, umjesto da za to pišete programski kod u Pythonu ili nekom drugom programskom jeziku.
Za normalno korištenje alata morate prvo napraviti besplatnu registraciju na web lokaciji https://www.octoparse.com, nakon čega dobivate probni period od 14 dana za upoznavanje s alatom. Nakon isteka tog perioda možete izabrati različite oblike komercijalnog korištenja i plaćanja na mjesečnoj razini. Ako vam se predložene cijene čine prevelike, uvijek možete posegnuti za nekim Python priručnikom, naučiti osnove programiranja i vratiti se prvom pristupu – pisanju programskog koda.
Kao registrirani korisnik možete preuzeti verziju alata za Windowse ili macOS, a nakon što definirate zadatke koje želite napraviti kod izdvajanja podataka s neke web lokacije, izvođenje možete pokrenuti i pomoću Octoparse cloud platforme. To ima puno smisla ako istovremeno želite strugati veći broj stranica. U takvim situacijama cloud infrastruktura će sigurno brže odraditi posao nego vaše lokalno računalo. Korištenjem cloud infrastrukture (pomoću nekog od standardnih preglednika) izvođenje je dostupno na svim operativnim sustavima.
Nakon instalacije i povezivanje lokalne aplikacije instalirane na vaše računalo s korisničkim računom na webu, možete započeti s nekim od scraping projekata. U alat je podrazumijevano ugrađena podrška za veliki broj najpoznatijih web lokacija u obliku svojevrsnih predložaka, jer se u praksi vrlo često koriste podaci s takvih izvora. Naravno, uvijek možete raditi i na svojem vlastitom projektu ispočetka, odnosno na web lokacijama koje sami izaberete.
Octoparse je opremljen vrlo dobrim vodičima za korištenje, što uključuje i prateće video sadržaje. Međutim, varate se ako mislite da ćete odmah nakon nekoliko minuta moći napraviti profesionalna scraping rješenja. Iako u ovom alatu zaista nećete morati programirati, trebate upoznati dosta mogućnosti alata, a možda čak naučiti i dodatne tehnologije s kojima se do tada niste susretali.
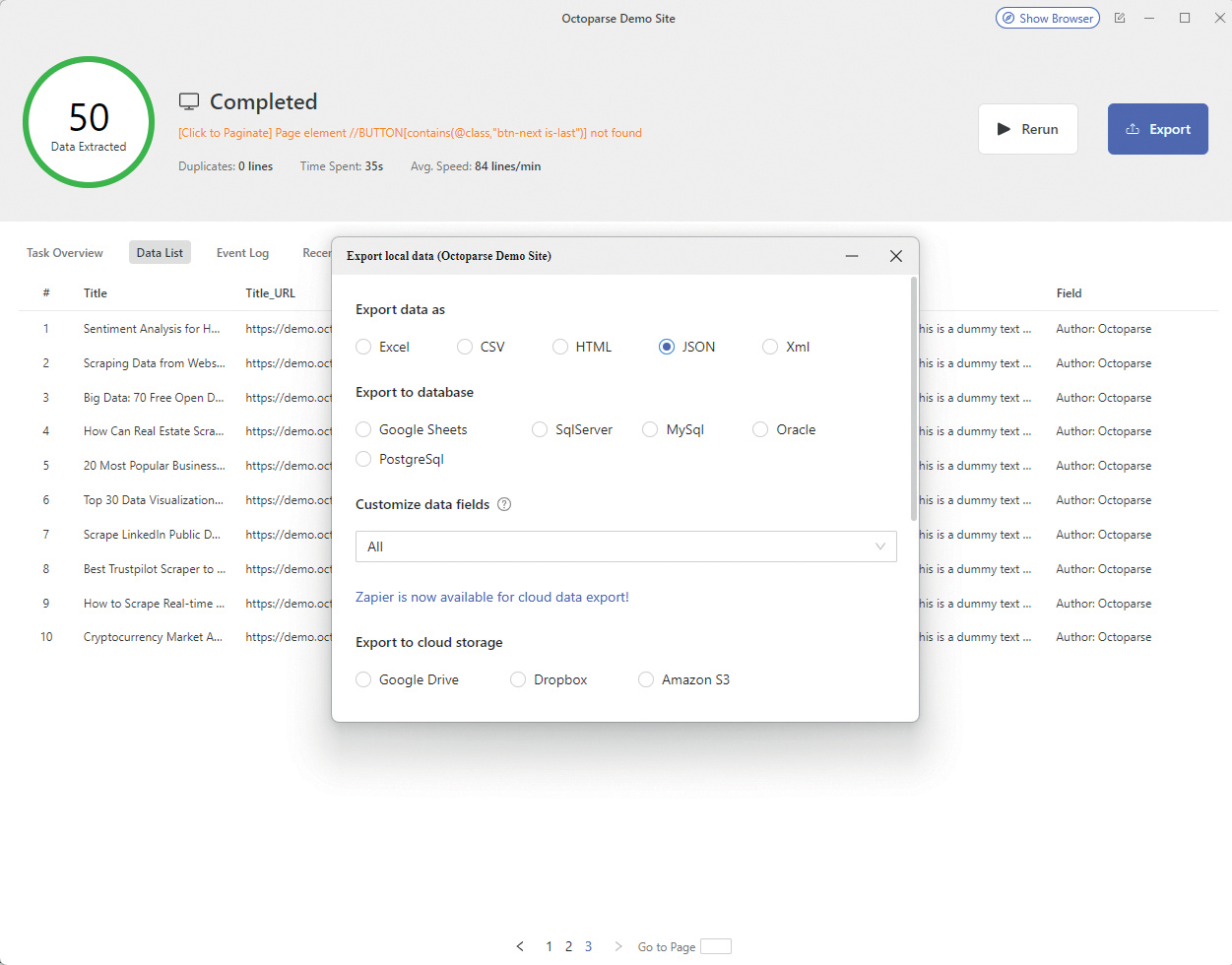
Nakon što napravite svoj Octoparse model za operaciju scrapinga na nekoj web lokaciji, možete birati u kojem ćete formatu napraviti izvoz prikupljenih podataka. To mogu biti neki od standardnih formata datoteka kao što su Excel, CSV, JSON ili XML, ali također izravno zapisivanje podataka u nekoliko najpopularnijih sustava za upravljanje bazama podataka, kao što su: Google Sheets, Microsoft SQL Server, MySql, Oracle ili PostgreSql. A za rukovanje s takvim bazama podataka morate imati (ili steći) bar nekakvo minimalno znanje iz tog područja.
Evo primjera kako izgleda primjer podataka preuzetih s demo web lokacije za testiranje alata (Octoparse Demo Site), u JSON formatu. Na vama je da kasnije definirate kako ćete koristiti takve podatke spremljene u datoteku ili neki objekt u bazi podataka.
[
{
“Title”: “Easy Steps to Scrape Product Listings from Rakuten”,
“Title_URL”: “https://demo.octoparse.com/1”,
“Description”: “As one of the most popular eCommerce sites in Japan, you can find many Japanese products in Rakuten. Reading this article, you can learn about how to ...”,
“Time”: “2022-08-05 16:43”,
“Title1”: “1. Lorem Ipsum”,
“Text”: “1. This is a dummy text article for testing purpose only.\n\n\n\n\nLorem ipsum dolor sit amet, consectetuer adipiscing elit. Aenean commodo ligula eget dolor. Aenean massa. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus.\n\n\n\n\nDonec quam felis, ultricies nec, pellentesque eu, pretium quis, sem. Nulla consequat massa quis enim. Donec pede justo, fringilla vel, aliquet nec, vulputate eget, arcu. In enim justo, rhoncus ut, imperdiet a, venenatis vitae, justo. Nullam dictum felis eu pede mollis pretium.\n\n\n\n\nInteger tincidunt. Cras dapibus. Vivamus elementum semper nisi. Aenean vulputate eleifend tellus. Aenean leo ligula, porttitor eu, consequat vitae, eleifend ac, enim. Aliquam lorem ante, dapibus in, viverra quis, feugiat a, tellus. Phasellus viverra nulla ut metus varius laoreet. Quisque rutrum.\n\n\n\n\nAenean imperdiet. Etiam ultricies nisi vel augue. Curabitur ullamcorper ultricies nisi. Nam eget dui. Etiam rhoncus. Maecenas tempus, tellus eget condimentum rhoncus, sem quam semper libero, sit amet adipiscing sem neque sed ipsum. Nam quam nunc, blandit vel, luctus pulvinar, hendrerit id, lorem.\n\n\n”,
“Field”: “Author: Octoparse”
},
Kao što je već ranije napomenuto, za samo izvođenje web scrapinga možete birati svoje lokalno računalo ili korištenje Octoparse cloud infrastrukture.
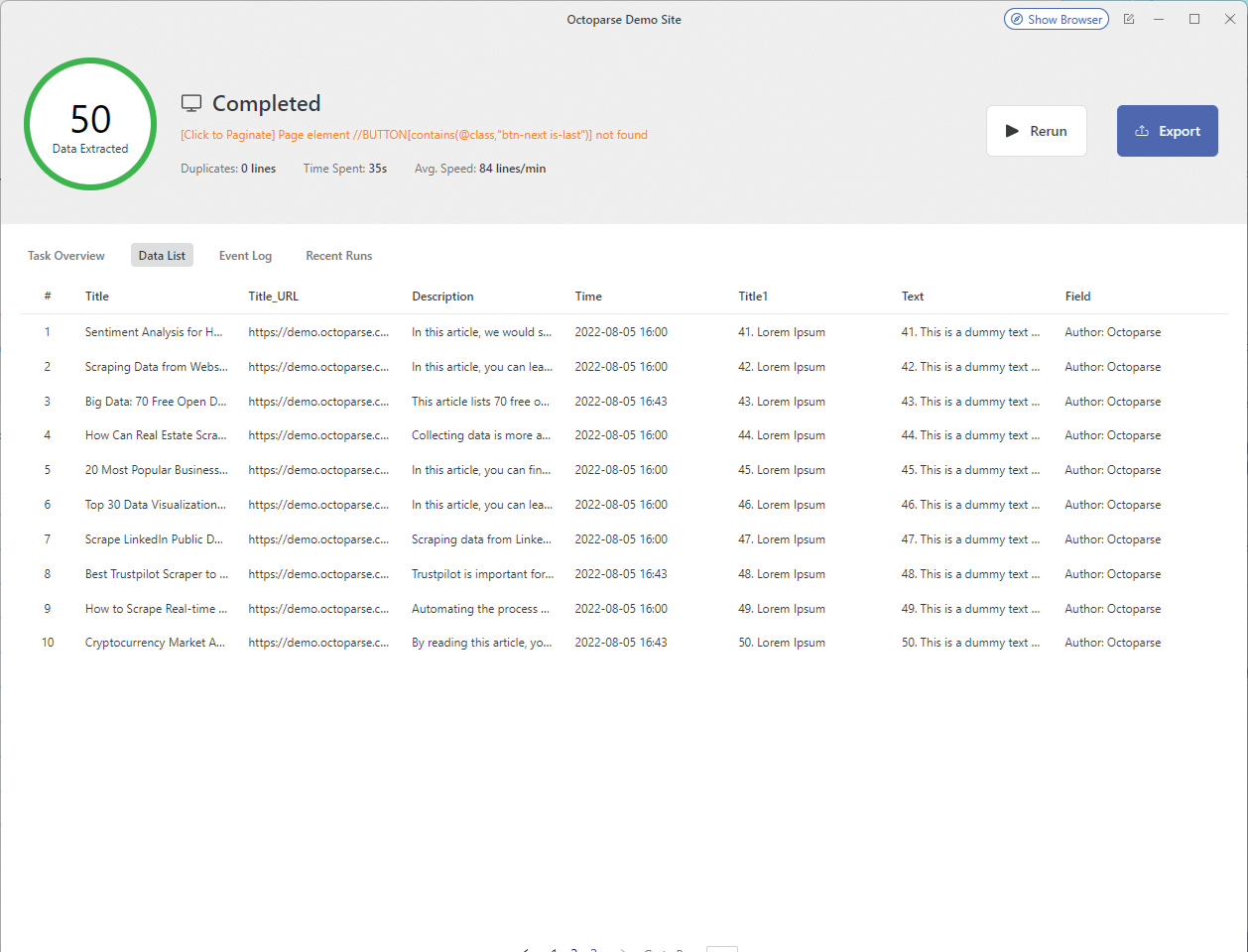
Rezultati izvođenja projekta: Pripremljeni rezultati mogu se detaljno pregledati na različite načine
Nekoliko rečenica o „pravnoj pozadini“
Iako smo na početku teksta spomenuli da se nećemo previše baviti pravnim problemima povezanim s ovim područjem, ipak navodimo nekoliko osnovnih smjernica.
Scraping podataka na webu se u pravilu smije izvoditi ako se to radi nad podacima koji su javno dostupni svima bez potrebe za prijavom na sustav, a nije dozvoljeno ako se za pristup podacima zahtijeva prijava na sustav ili postoji neki drugi oblik zaštite.
Tijekom scrapinga ne bi se smjeli prikupljati osobni podaci (pogotovo u EU zbog GDPR-a), ne bi se smjele ignorirati ni smjernice za konkretnu web lokaciju postavljenje u dobro poznatoj datoteci robots.txt, niti bi taj postupak smio biti takav da preopterećuje resurse servera, odnosno da izgleda kao DDoS (Distributed Denial of Service) napad na analiziranu web lokaciju.
Prilikom pripreme web scraping procedure trebalo bi provjeriti i to ne krše li se tim postupkom posebni uvjeti korištenja određene web lokacije, što uključuje i različite autorske sadržaje.
U slučaju da se do istih podataka za neku web lokaciju može doći korištenjem API poziva koje nudi ta ista web lokacija, onda je pravno sigurnije koristiti takav način prikupljanja podataka. Problem je u tome što legalno korištenje API-ja može zahtijevati plaćanje pristupa podacima, dok web scraping može biti puno jeftiniji ili čak besplatan.
Evo konkretnog primjera prije spomenute razlike između (legalnog) korištenja API-ja i (nelegalnog) postupka web scrapinga radi prikupljanja istih podataka. Pretplata na pristup vrijednim podacima (na primjer, onima povezanim s financijskim tržištima ili tržištima naftnih derivata i drugih ugljikovodika) pomoću API poziva može biti tehnički vrlo jednostavno, ali zato može zahtijevati godišnju pretplatu za korištenje reda više tisuća dolara. Istovremeno pristup tim istim podacima tako da kupite nekakav „login“ za tu istu web lokaciju može biti jeftiniji čitav red veličine. Jednostavno vas „vuče“ da izaberete nelegalni scraping sadržaja nakon legalne prijave na web lokaciju te tako uštedite gomilu novca, zar ne?
Nadamo se da ste na temelju ovog teksta razumjeli što su i kako se za vlastite potrebe mogu implementirati web crawling i web scraping. U slučaju da vam zatreba pomoć kod nekog zahtjevnijeg scraping projekta na „programerski način“, možete se preko redakcije obratiti autoru teksta za konzultacije.