O tehnologijama lakehouse i warehouse već smo nekoliko puta pisali u časopisu, ali nekako više s njihove „teoretske strane“. Ovaj put ćemo demonstrirati kako obje spomenute tehnologije djeluju u praksi, uz pomoć najnovije Microsoftove platforme za jedinstveno rukovanje različitim vrstama podataka – Microsoft Fabric (u nastavku teksta MF). Primjere koje ćemo prikazati i opisati u nastavku možete bez nekakvih posebnih troškova isprobati sami. Kao i brojne druge Microsoftove tehnologije, tako je i MF dostupan za besplatno korištenje u vremenski ograničenom probnom periodu (60 dana).
Mjesto odakle možete započeti s probnim korištenjem i detaljnijim istraživanjem MF-a je web adresa https://www.microsoft.com/en-us/microsoft-fabric/getting-started. Naglasimo usput da je tijekom probnog korištenja MF-a na raspolaganju prilično „jaka konfiguracija“ sustava, kakva se inače tijekom komercijalnog korištenja prilično naplaćuje. To je donekle i logično, jer Microsoft sigurno ne želi da imate probleme s performansama tijekom perioda probnog korištenja.

Microsoft Fabric: Na raspolaganju je korištenje besplatne verzije u trajanju od 60 dana
Nakon dovršetka prijave na probnu instancu MF-a, na raspolaganju su brojne mogućnosti sustava u pogledu spremanja, obrade, analize i prikaza podataka. U današnjem tekstu ćemo se prije svega orijentirati na samo spremanje podataka, kako bismo mogli demonstrirati lakehouse i warehouse tehnologiju, njihovu međusobnu povezanost, ali i razlike.
Demonstraciju započnite tako da na početnoj stranici izaberete naredbu New Item, a nakon toga iz ponuđenog popisa dostupnih opcija Lakehouse. Kao rezultat izvođenja prethodne operacije, nakon nekog vremena potrebnog za automatsku konfiguraciju, pojavit će se vaše prvo lakehouse skladište podataka. Kako bismo mogli što jednostavnije demonstrirati rad s podacima (bez potrebe za upisivanjem vlastitih primjera), možete odmah izabrati punjenje tog spremišta s primjerima podataka. Opcija je dostupna na pozadini početne stranice skladišta.
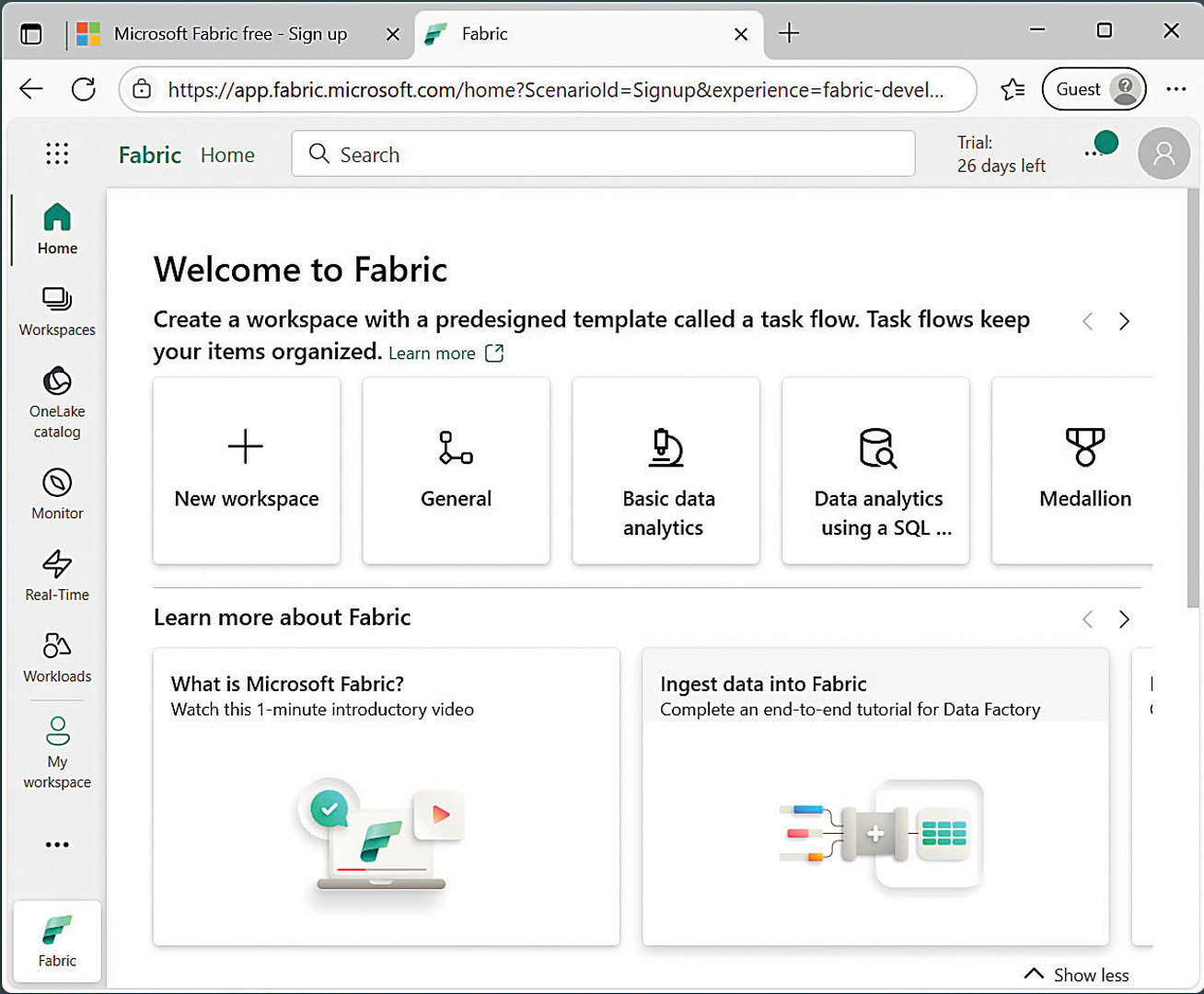
Microsoft Fabric moduli: nude vam brojne tehnologije
Kolekcije podataka
Korisnicima je na raspolaganju nekoliko različitih demo zbirki podataka. Ako želite što jednostavnije pratiti primjere iz ovog teksta, onda izaberite kolekciju podataka s podacima o taksi vožnjama izmišljene kompanije koja nudi takve usluge.
Kao rezultat izvođenja prethodne operacije u lijevom dijelu stranice, u hijerarhijskom prikazu dostupnih tablica u sustavu, pojavit će se stvarne tablice s podacima. Za svaku od tablica možete u tom lijevom dijelu prikaza pregledati njezinu strukturu (nazive stupaca i slično), a u desnom dijelu same podatke u uobičajenom tabličnom obliku prikaza.
Klikom na oznaku s tri točke na vrhu svake kolone, podatke u kolonama možete po želji sortirati ili pretraživati, ali bi to otprilike bilo sve što možete napraviti. U ovom trenutku neku drugu priliku, spomenimo (kao primjer) da su takvi podaci u lakehouse tablicama izravno dostupni za različite vrste obrade u okviru MF cjevovoda (pipelines).
Međutim, što ako želite koristiti podatke na nešto fleksibilniji način? Na primjer, umjesto da filtriranje podataka izvodite preko izbornika na vrhu svakog stupca tablice, zar ne bi bilo zgodno da možete postavljati različite vrste SQL upita? Jer je to jezik kojeg već dobro poznajete otprije.
To je mjesto na kojem u igru ulazi warehouse dio MF-a. Ako pogledate prateću sliku uz tekst, ili to sami provjerite u MF-u (pokrenuli ste ga i napunili demo podacima, zar ne), možete primijetiti da se u spremištu podataka osim lakehouse dijela, nalazi i odgovarajući semantički model, odnosno SQL Analytics dio. Ako sada pokušate pregledavati sadržaj istoimene tablice, na raspolaganju vam je i mogućnost postavljanja SQL upita. Na primjer, najnormalnije možete upisivati različite oblike SQL SELECT naredbi, uključujući WHERE ili ORDER BY dijelove. To je upravo ono što nudi povezanost warehouse i lakehouse dijelova u okviru istog sustava, to jest MF-a.
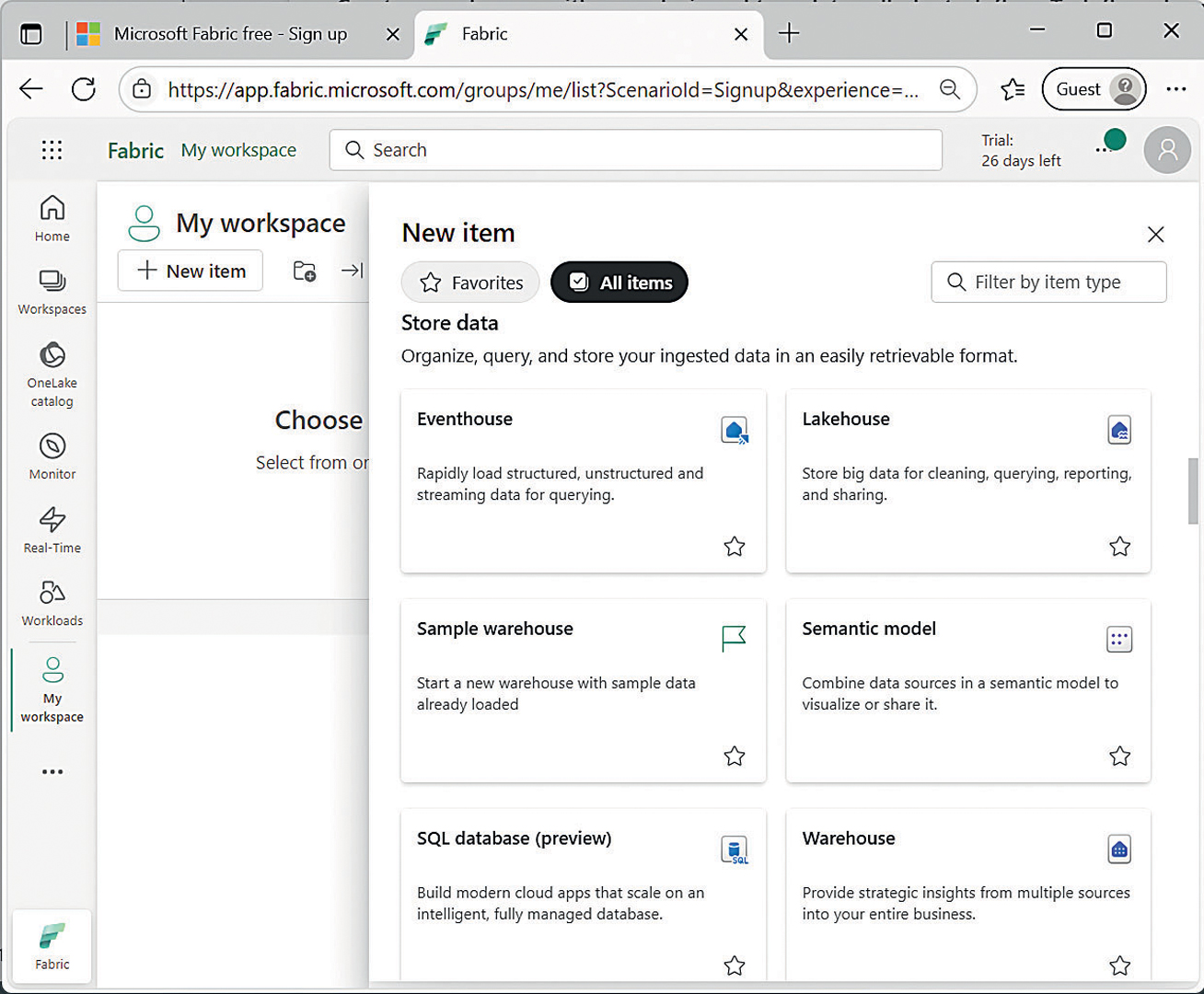
Lakehouse: Prvo je potrebno izabrati i aktivirati ovaj modul
Lakehouse i warehouse
Treba istaknuti da na ovaj način ipak nisu izravno dostupne sve mogućnosti SQL jezika koje je moguće koristiti izravno u relacijskoj bazi kao što je SQL Server. Na primjer, napredna SQL MERGE naredba. A neki drugi dijelovi, iako formalno postoje (kao što je JOIN dio za povezivanje tablica), postaju praktično neupotrebljivi kad ih se pokuša koristiti u vrlo složenim primjerima. Na primjer, povezivanje većeg broja tablica pomoću JOIN dijela je izvedivo, ali samo do određenog stupnja složenosti. Nakon toga se naredba najčešće počinje izvoditi „beskonačno dugo“, to jest, sve skupa postaje neupotrebljivo.
U slučaju da je potrebno izvođenje vrlo složenih obrada nad podacima, to možete napraviti prepisivanjem tih istih SQL naredbi u odgovarajući Notebook element, ili pisanjem odgovarajućeg Python, Scala ili R koda, čime postižete još veći stupanj fleksibilnosti u obradi. Ali to je već tema za neku drugu priliku.

Demo podaci: Na početku korištenja postoji mogućnost uvoza demo podataka

Lakehouse tablice: Pregled podataka i dostupne opcije
Da bi čitava stvar bila još ljepša, uz pomoć odgovarajuće ikone u warehouse dijelu možete generirati niz znakova za povezivanje (takozvani Connection String) pomoću kojeg se na MF warehouse dio možete spojiti preko standardnog desktop alata za tu namjenu (SQL Server Management Studio).
A to onda znači da su vam na raspolaganju sve mogućnosti alata u pogledu uređivanja SQL koda na mnogo napredniji način nego što je to moguće izravno u MF. Još jednu stvar koju svakako treba uzeti u obzir kod paralelnog korištenja lakehouse i warehouse dijela je određeno vrijeme potrebno da se između njih napravi sinkronizacija podataka. Ako korištenjem neke od dostupnih tehnologija obrade, kao što su cjevovodi, u Parquet (znači lakehouse) tablicu uvezete veliki broj slogova (reda veličine nekoliko stotina tisuća slogova i više), ti isti podaci nisu odmah dostupni u warehouse SQL upitima. Na primjer, ako probate napraviti SQL SELECT upit za provjeru dijela takvih podataka, može vam se dogoditi da ih ne vidite, iako je s prijenosom podataka u lakehouse tablice sve bilo u redu.

Parquet format: Podatkovni format u kojem su spremljeni podaci iz tablica
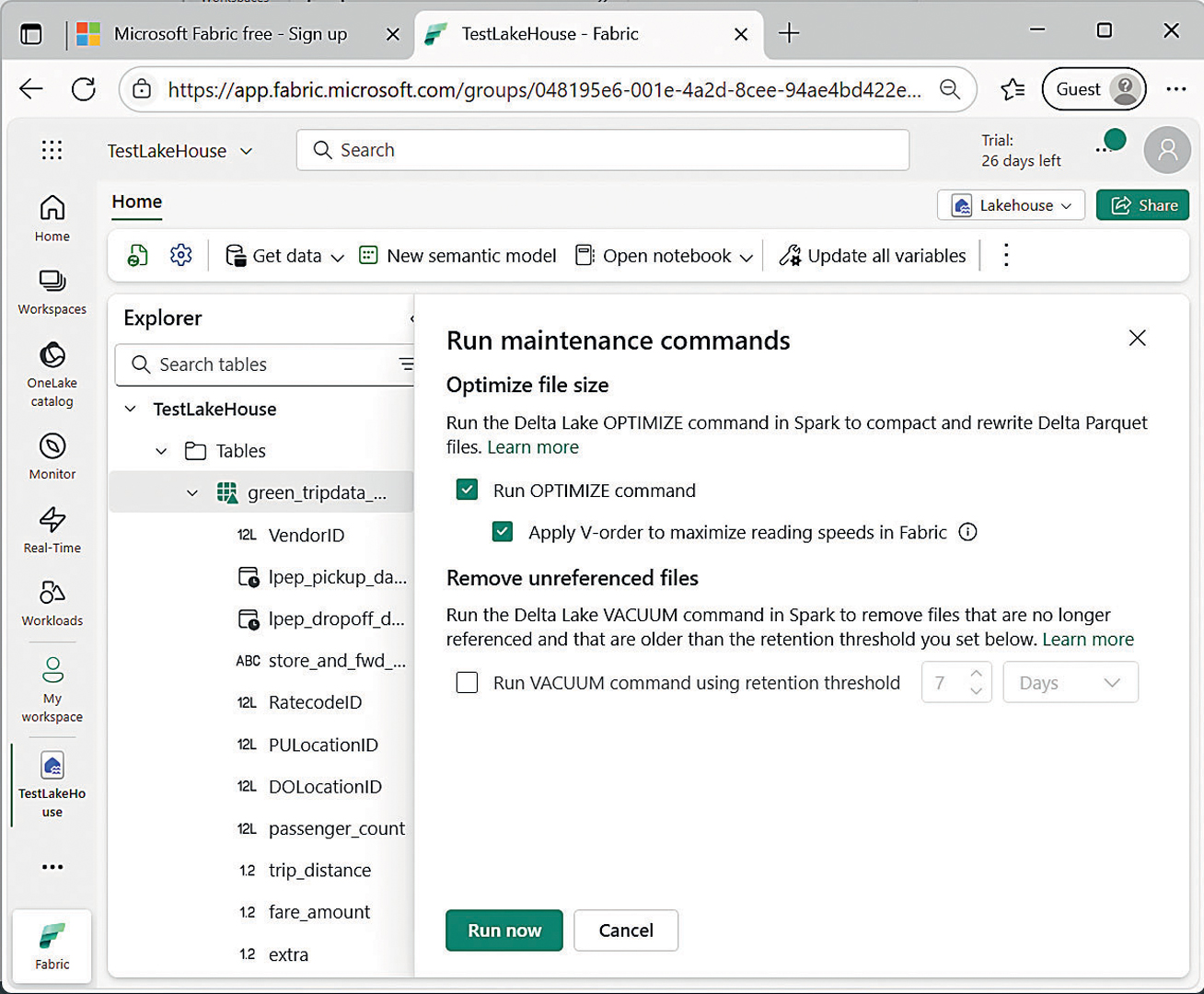
Održavanje tablica: Optimizacija i uklanjanje starih podataka
Drugim riječima, potrebno je određeno vrijeme da ti isti podaci „sazriju“ i u warehouse dijelu, odnosno da se izvede odgovarajuća sinkronizacija podataka. Nakon određenog vremena (recimo, nekoliko minuta), potpuno ista SQL naredba prikazat će podatke koje ste očekivali, iako u međuvremenu nije bilo nikakve obrade ni izmjene podataka. Vrijedi i obrnuto. U slučaju brisanja velike količine podataka, moguće je da i dalje vidite njihovu fantomsku kopiju u vlastitih upitima.
Budući da je kvalitetu podataka dobivenu iz postavljenog upita u najmanju ruku neozbiljno temeljiti na „sazrijevanju“ podataka, sasvim je logično da mora postojati mehanizam kojim se takva operacija zahtijeva po potrebi. Riječ je o dobro poznatoj naredbi Refresh dostupnoj u hijerarhijskoj strukturi prikaza tablica u warehouse dijelu, ili o posebnom elementu za sinkronizaciju semantičkih podataka u okviru cjevovoda. Na taj način možete biti sigurni da su u određenom trenutku podaci jednaki i u lakehouse i u warehouse dijelu.
Nadamo se da vam je nakon današnjeg teksta jasnije kako navedena dva dijela sustava za spremanje podataka međusobno djeluju u praksi, kako bi se moglo iskoristiti ono najbolje od oba dijela.

Semantic model: dostupan je kao nadogradnja osnovnih Parquet tablica