






Ako bar ponekad pratite ili koristite dio IT tehnologije povezan s podacima, odnosno njihovim skladištenjem i korištenjem, onda ste se sigurno već susreli s pojmom „Data Warehouse“ (skladište podataka). Budući da „klasično“ skladište podataka nije pogodno za skladištenje svih podataka koji se pojavljuju u modernoj praksi, zadnjih godina sve intenzivnije se koriste još dvije dodatne arhitekture. To su Data Lake i Data Lakehouse. Dok se za prvi pojam već prilično udomaćio domaći prijevod „podatkovno jezero“, za drugi pojam (zbog njegove novosti) tek treba smisliti pravi prijevod.
Zbog jednostavnosti u pisanju, u nastavku teksta najčešće ćemo koristiti sljedeća tri skraćena naziva: warehouse, lake i lakehouse.
Kratki uvod
U današnje vrijeme vjerojatno je potpuno nepotrebno objašnjavati kako smo i na privatnom i na poslovnom planu podvrgnuti pravom „bombardiranju podacima“ iz različitih izvora. Ako se u nastavku izlaganja usredotočimo na poslovni sektor, neki od izvora podataka s relevantnim podacima (formalnim ili neformalnim) o tvrtki i njezinom poslovanju su:
- Interni IT sustav
- Dokumenti u različitim formatima koji se ne čuvaju izravno u IT sustavu (npr. Word, Excel ili PDF dokumenti i slično)
- E-mail i ostali oblici komunikacije s partnerima i kupcima (npr. Teams, Zoom, Skype i slično)
- Podaci dostupni na različitim web servisima (banke, državna uprava, druge tvrtke i slično)
- Društvene mreže
- Različite vrste medija, uključujući video servise
- Različiti IoT (Internet of Things) podaci, itd.
Spremanje svih nabrojenih vrsta podataka u jedinstveno skladište podataka, te mogućnost naknadnog pristupa svim relevantnim podacima postaje jedan od najvećih izazova u modernom poslovanju. Pri tome uvijek treba uzeti u obzir i cijenu implementacije te naknadnog korištenja takvog skladišta. Zato nije previše čudno da je došlo do pojave različitih arhitektura skladišta podataka, kako bi se što bolje zadovoljili svi postavljeni zahtjevi.
1. Data Warehouse
Kod ovakve najstarije i najpoznatije arhitekture za čuvanje podataka, skladište podataka se u pravilu temelji na relacijskom modelu. Izvori podataka za warehouse mogu biti u različitom obliku, ali se prije spremanja u warehouse oni moraju pripremiti tako da budu pogodni za čuvanje u relacijskom (drugim riječima, dobro strukturiranom) obliku. Za to se najčešće koriste različite vrste ELT (Extract, Load, Transform) ili ETL (Extract, Transform, Load) procesa.
Nakon spremanja podataka u warehouse, svi podaci su brzo i jednostavno dostupni za pretraživanje i korištenje. Za to se mogu koristiti različite vrste BI (Business Intelligence) alata, ali se podacima može pristupati i izravno pomoću dobro poznatog jezika upita SQL, ili uz pomoć različitih dodatnih aplikacija koje prepoznaju warehouse kao oblik skladištenja podataka. Nabrojeno ujedno predstavlja glavnu prednost spremanja podataka u warehouse.
Najveći nedostatak navedenog pristupa je nefleksibilnost u korištenju polustrukturiranih ili nestrukturiranih podataka. Neke od ranije nabrojenih vrsta podataka je u modernom poslovnom okruženju prilično teško, ili čak nemoguće uklopiti u warehouse. Ili je to moguće napraviti tek nakon manjeg ili većeg broja promjena u postojećoj strukturi skladišta. Ako dio izvornih podataka zbog svoje nestrukturiranosti nije moguće uključiti u warehouse, onda to za posljedicu ima smanjenje kvalitete i pouzdanosti različitih analiza koje se naknadno provode nad podacima. Uključujući i korištenje sve popularnijih AI tehnika analize i razumijevanja podataka.
Drugi, prilično veliki nedostatak warehouse arhitekture u odnosu na druge dvije arhitekture, o kojima će više riječi biti nešto kasnije, jest veća cijena korištenja. Proširivanje warehouse skladišta (kako bi se u njega mogli smjestiti novi podaci) u pravilu zahtijeva ulaganje najviše financijskih sredstava od sve tri nabrojene tehnologije. Posebice ako osim samog fizičkog proširivanja skladišta treba napraviti i promjene u strukturi, i/ili pripremiti nove ETL/ELT procese za učitavanje podataka.
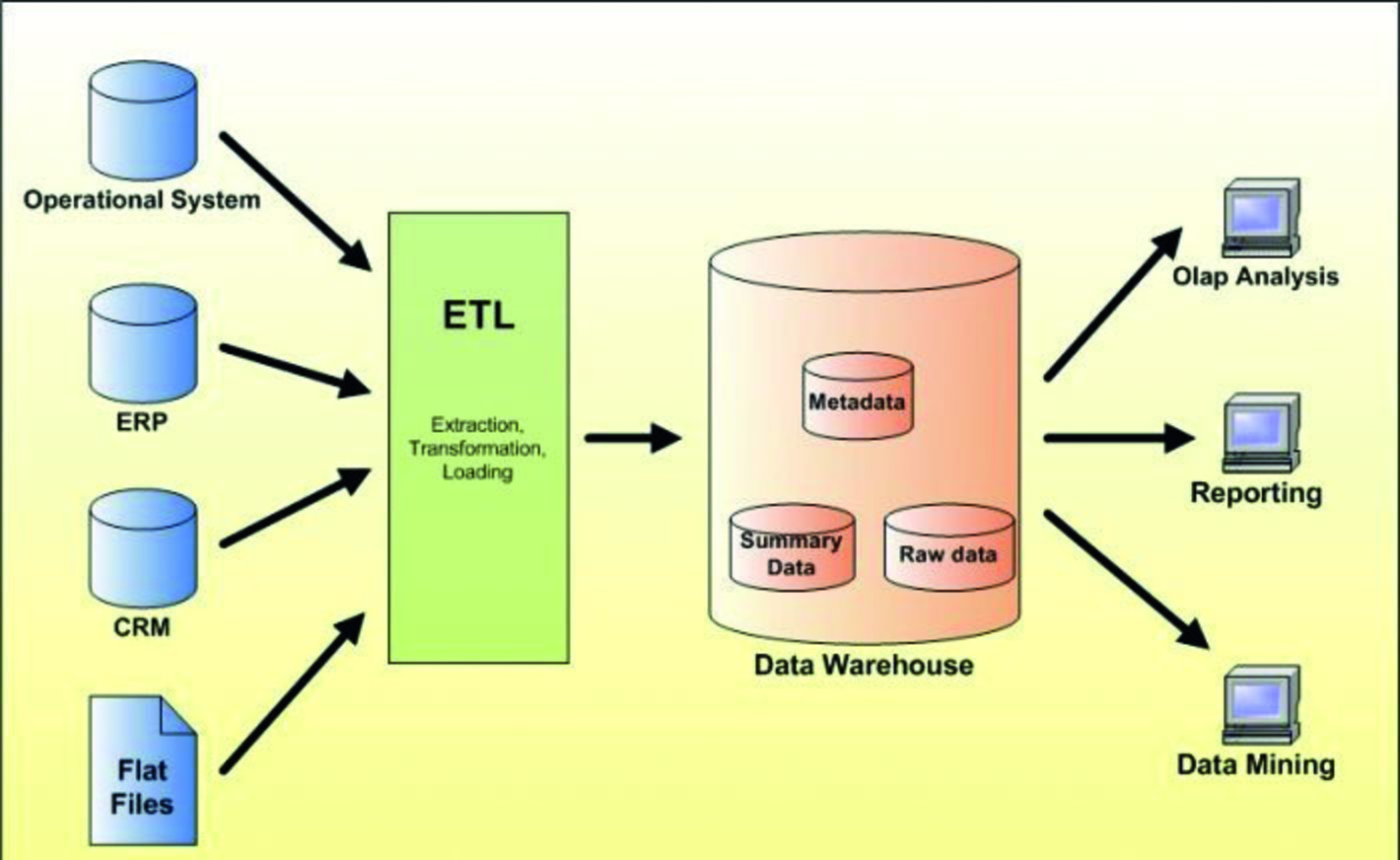
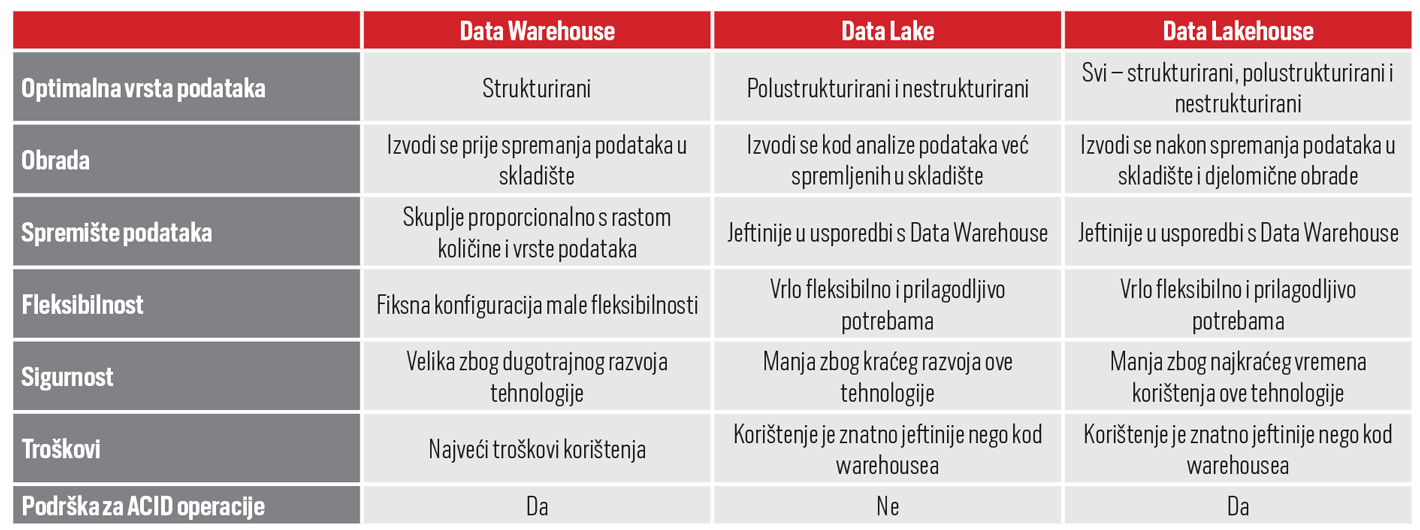
Data Warehouse: Prije spremanja podataka u skladište izvodi se priprema podataka pomoću različitih ETL/ELT operacija
2. Data Lake
Kako bi se svi postojeći podaci, a ne samo strukturirani, mogli čuvati na jednom mjestu zbog naknadnog korištenja (ako i kada se za tim ukaže potreba), razvijeno je takozvano „podatkovno jezero“ ili Data Lake.
Kod ovakvog načina skladištenja podataka, svi podaci se čuvaju u svojem izvornom obliku. To znači da se u lake arhitekturi mogu zajedno čuvati i strukturirani (najčešće relacijski) podaci, ali i različite vrste polustrukturiranih ili nestrukturiranih podataka. Podaci se obuhvaćaju i spremaju u lake bez potrebe za prethodnim korištenjem ETL/ELT procedura, kao što je to slučaj kod warehousea.
ETL/ELT procedure se pripremaju i koriste samo kad su određeni podaci već spremljeni u lake zaista potrebni za dodatne analize. A to u pravilu smanjuje cijenu njihove pripreme i korištenja u odnosu na warehouse.
Dodatne prednosti podatkovnog jezera u odnosu na skladište ogledaju se u tome što:
- ne treba izvoditi nikakva posebna prilagođavanja u arhitekturi da bi se počelo sa spremanjem nove vrste podataka
- samo spremanje podataka u izvornom obliku je jeftinije, jer nema potrebe za korištenjem nekakvog relacijskog sustava za obuhvat podataka koje u pravilu dolazi uz naplatu
- budući da se svi podaci spremaju u izvornom obliku, za njihovo korištenje se mogu koristiti različiti specijalizirani alati za obradu pojedine vrste podataka
Spremanje podataka u jezero u njihovom izvornom obliku dovodi i do dva bitna nedostatka:
- podaci u jezeru ne moraju biti međusobno konzistentni, a postoji i mogućnost brojnih redundancija
- u slučaju da je za određenu vrstu obrade podataka potrebno pristupiti različitim vrstama izvornih podataka, takav pristup ne mora biti baš optimalan u pogledu performansi.
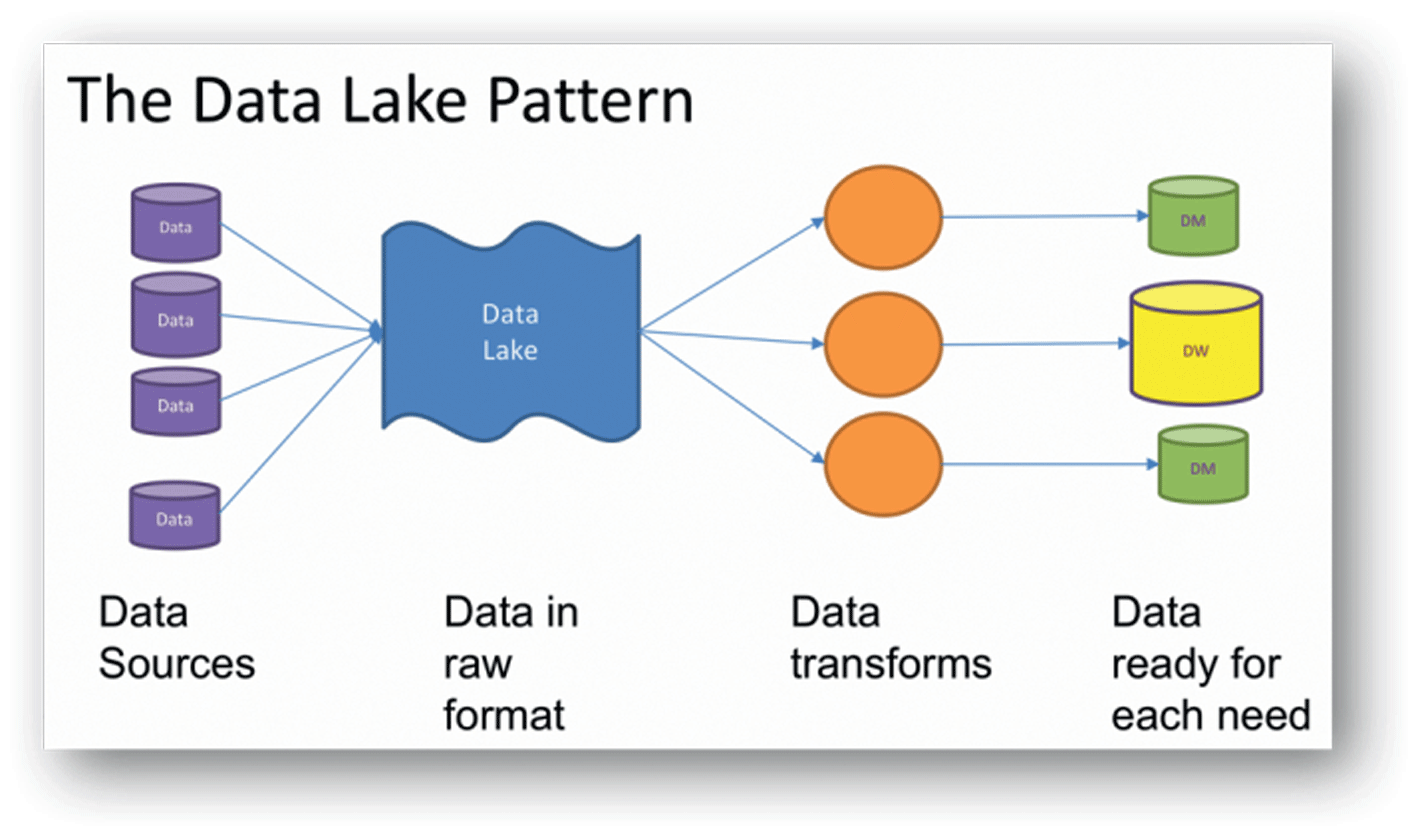
Data Lake: Podaci se spremaju u izvornom obliku, a ETL/ELT operacije se izvode tek kada je to zaista potrebno
3. Data Lakehouse
Data Lakehouse predstavlja najnoviju arhitekturu spremišta podataka koja pokušava objediniti najbolje strane obje ranije spomenute arhitekture: Data Warehouse i Data Lake. Kao i lake, tako i lakehouse omogućava izravno spremanje različitih vrsta podataka (strukturiranih, polustrukturiranih i nestrukturiranih). Ono što je novost i unapređenje u odnosu na obično podatkovno jezero je to što se podaci nakon učitavanja konvertiraju u poseban format zadužen za povećanje sigurnosti i pouzdanosti podataka uz istovremeno smanjenje redundancije. Drugim riječima, o lakehouse arhitekturi se može razmišljati kao o svojevrsnom skladištu (warehouse) uspostavljenom „iznad“ podatkovnog jezera (lake).
Primjer frameworka odnosno okvira pod nazivom „Delta Lake“, pomoću kojeg se lake arhitektura može pretvoriti u lakehouse, dostupan je na web adresi: https://delta.io/
U odnosu na warehouse, također su smanjeni troškovi korištenja kao i kod obične lake arhitekture. Zbog mogućnosti korištenja izvornog oblika dokumenata, ali i već obrađenih podataka (na primjer, pomoću ranije spomenutog frameworka), lakehouse je iskoristiv za različite mogućnosti primjene, odnosno za različite alate za obradu podataka.
Najveći nedostatak lakehouse arhitekture ogleda se u njezinoj relativnoj novosti u odnosu na druge dvije arhitekture, tako da u ovom trenutku zapravo još uvijek postoje i određene nedoumice oko njezinog prihvaćanja u praksi.
Međusobna usporedba različitih arhitektura podataka prikazana je u sljedećoj tablici te na pratećoj slici uz tekst (izvor: https://serokell.io/blog/data-warehouse-vs-lake-vs-lakehouse). Preko ove adrese omogućen je pristup malo dužem tekstu o teorijskoj osnovi za novu arhitekturu skladišta podataka:
https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
Data Lakehouse: Podaci se spremaju u izvornom obliku, ali se nakon toga odmah dodatno obrađuju da bi kasnije bili jednostavniji za korištenje
USPOREDBA

Delta Lake: Primjer frameworka za pretvaranje Data Lake arhitekture u Data Lakehouse
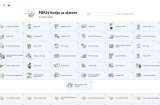
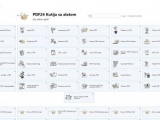
ETL primjer
U prethodnom dijelu teksta nekoliko puta smo spomenuli potrebu za korištenjem ETL ili ELT procesa tijekom pripreme podataka u različitim arhitekturama skladišta podataka. Za čitatelje koji se do sada nisu susretali s ovakvim postupcima, u nastavku teksta ćemo ukratko objasniti o čemu je riječ.
Pri tome ćemo za objašnjenje primjera koristiti cloud tehnologiju Microsoft Azure.
Od strane Microsofta je trenutno preporučeni i ujedno najnoviji način za pristup podacima s različitih izvora, njihovu transformaciju i spremanje u željeni odredišni oblik priprema odgovarajućeg cjevovoda (pipeline). Kao alat za pripremu cjevovoda se pri tome koristi alat Azure Synapse Studio. Po potrebi se cjevovod može pripremiti za pristup i uvlačenje podataka iz vanjskih izvora (tipična primjena kod warehouse arhitekture), odnosno za pristup podacima koji se već nalaze u podatkovnom jezeru (lake ili lakehouse).
U okviru jednog cjevovoda mogu se koristiti različite vrste elemenata (aktivnosti) kako bi se moglo pristupiti različitim izvorima podataka kao što su relacijske ili NoSQL baze podataka, web servisi, različiti formati datoteka (npr. .csv), i tako dalje. Budući da i odredišta mogu biti definirana na različite načine, cjevovodi pripremljeni pomoću Azure Synapse tehnologije mogu se koristiti i za prijenos i/ili obradu podataka između izvora i odredišta koji nemaju izravne veze s Microsoftom.
Kako izgleda primjer jednog jednostavnijeg cjevovoda možete vidjeti na pratećoj slici uz tekst. U njemu se koristi nekoliko različitih elemenata, da bi se podaci koji se dobivaju iz web servisa spremili u relacijsku bazu u okviru Microsoft Azure platforme. Budući da je izvorne podatke često prilično komplicirano izravno zapisati u više različitih odredišnih tablica (pogotovo ako nakon početnog obuhvata treba napraviti određene korekcije podataka), podaci se mogu prvo zapisati u pomoćnu relacijsku tablicu. Tek nakon toga se u drugom koraku zapisuju u prave odredišne tablice. Slijedi kratko objašnjenje elemenata korištenih u pripremi cjevovoda. Naravno, detaljno objašnjenje svih mogućnosti svakog pojedinog elementa daleko prelazi okvire ovog teksta.
GetKeyVault
Element cjevovoda zadužen za čitanje lozinke potrebne za naknadni pristup web servisu. Da se lozinka ne bi mogla vidjeti izravno u cjevovodu zbog povećanja sigurnosti njegovog korištenja, ona je spremljena u posebno Microsoft spremište osjetljivih podataka (Key Vault).
WebSource 2 SQLTMP
Pomoću ovog elementa pristupa se web servisu, a on vraća podatke u JSON formatu. U okviru ovog elementa napravljeno je i takozvano mapiranje, kojim se određuje način prepisivanja izvornih JSON podataka u stupce pomoćne relacijske tablice. Tijekom ovog postupka ponekad je izvorne podatke potrebno razdvojiti u više stupaca, međusobno ih povezati, ili napraviti još složenije transformacije.
CorrectData
Nakon što su pomoću prethodnog elementa podaci preneseni u pomoćnu tablicu, u ovom elementu se nalazi nekoliko standardnih naredbi za sređivanje neispravnih ili neprikladnih izvornih podataka. Na primjer, web servis vraća podatke o osobi s naznakom Ms ili Mr, a za korištenje u novom sustavu potrebno je imati hrvatske inačice: gospođa i gospodin. Budući da se podaci već nalaze u relacijskom modelu, za to se u okviru ovog elementa mogu koristiti standardne SQL naredbe poput UPDATE.
SQLTMP 2 Table 1, SQLTMP 2 Table 2, SQLTMP 2 Table 3
Tri elementa za kopiranje dijela odgovarajućih podataka iz pomoćne relacijske tablice u tri „prave“ odredišne tablice potrebne za korištenje u novom sustavu. Pri tome se može izabrati prethodno brisanje postojećih podataka u odredišnim tablicama, što znači da se svi podaci pune ispočetka, ili takozvana UPSERT operacija kod koje se prema potrebi podaci automatski dodaju ili ažuriraju. Naravno, u sva tri elementa potrebno je ponovno napraviti međusobno mapiranje stupaca početne pomoćne tablice i stupaca odredišnih tablica.
Primijetite da se na ovom mjestu cjevovod grana u tri odvojene linije koje se izvode paralelno, da bi se nakon toga ponovno skupile u jednu liniju izvođenja na zadnjem elementu cjevovoda. Paralelno izvođenje većeg broja operacija ubrzava rad tog dijela cjevovoda u odnosu na slijedno izvođenje.
Naravno, praktično je nemoguće za očekivati da će sve tri linije završiti istovremeno s izvođenjem, ali to nije nikakav problem u praksi. Azure Synapse brine o tome da izvođenje sljedećeg elementa započne tek kad se dovrše sve tri linije.
Report Error
U slučaju da su se tijekom postupka pojavili nekakvi problemi ili je sve prošlo OK, završni izvještaj zapisuje se u dodatnu relacijsku tablicu za naknadni pregled uspješnosti prijenosa. Za to se ponovno mogu koristiti standardne SQL naredbe.
Prilikom pripreme cjevovoda se osim osnovnih elemenata mogu koristiti i različiti parametri, odnosno varijable. Korištenjem parametara mogu se definirati cjevovodi koji se različito izvode ovisno o zadanim datumima za obuhvat podataka. Varijable se mogu iskoristiti za privremeno čuvanje različitih podataka potrebnih za normalno izvođenje cjevovoda. Na primjer, u jednom pristupu web servisu nije moguće pročitati sve podatke, nego se to mora raditi stranicu po stranicu. Stranica kojoj se trenutno pristupa i njezina veličina predstavljaju tipičan primjer korištenja vrijednosti u elementima cjevovoda zaduženima za ponavljanje izvođenja određenih operacija.
Nadamo se da su vam nakon čitanja ovog teksta jasnije različite moderne arhitekture za skladištenje velike količine podataka, odnosno uloga ETL/ELT procesa u čitavoj priči.
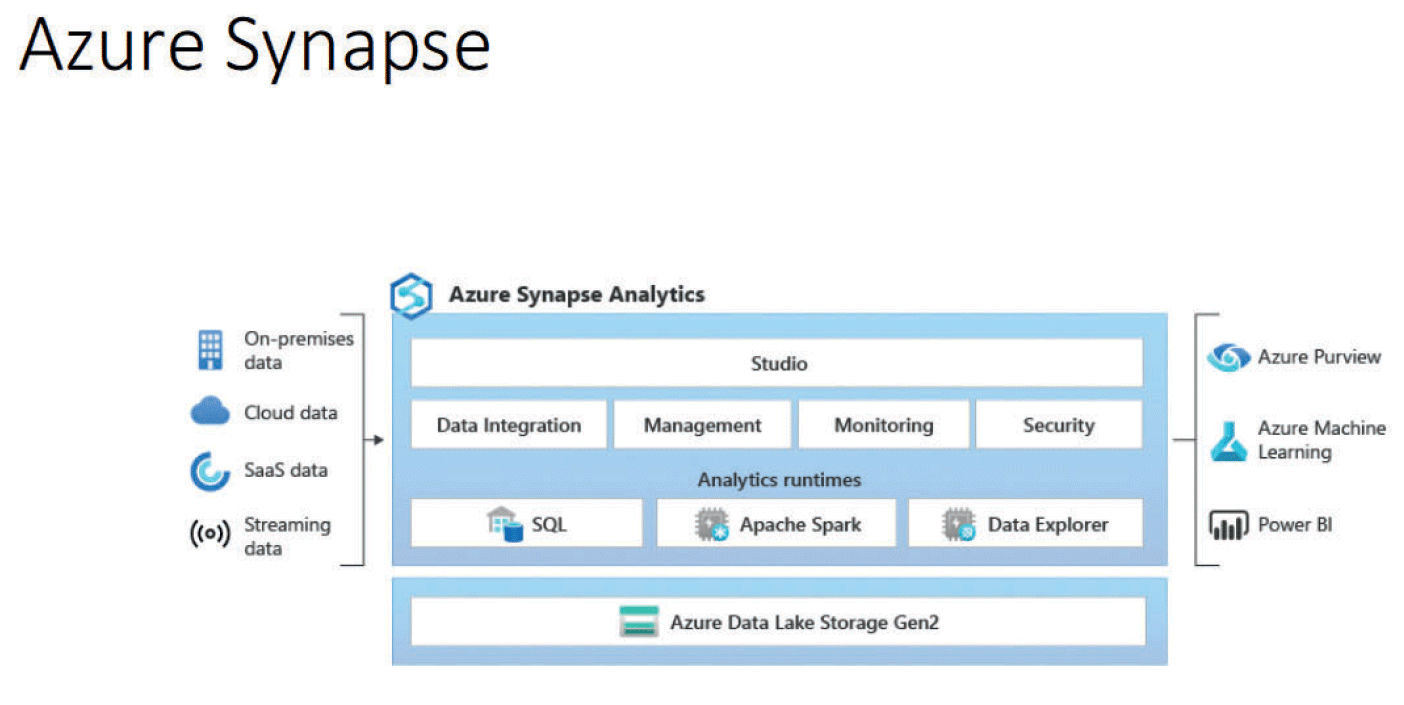
Azure Synapse: Osnovni moduli i arhitektura sustava